RE/flex
A fast lexical analyzer generator for C++
RE/flex is a high-performance C++ regex library and lexical analyzer generator. Extends Flex++ with Unicode, indent/dedent anchors, lazy quantifiers, functions for lex and syntax error reporting and much more. Seamlessly integrates with Bison and other parsers.
Spontaneous compliments and kudos
"Thank you for making this awesome library freely available! Wouldn't know what to do without it." -Atmaks on GitHub
"First of all thanks for amazing tool!! It's so cool!" -ivan-khudyashev on GitHub
"This project is awesome!" -DaOnlyOwner on GitHub
"Easy to use, out of the box support for moving from flex. Additional syntactic features for generating regexp. Matcher functionality in rules sections enables additional options for distributing logic between parser and lexer. Compatible with UTF16 input, which was a great deal [to have] for my application." -arietz on SourceForge
"It's a fast and very user friendly flex derivative c++ scanner which provides more functionality over Flex." -imran7 on SourceForge
"I ended up writing a little code around this but nothing as sophisticated as the wonderfulness you have done here." -koothkeeper on CodeProject
How does RE/flex work?
The RE/flex lexical analyzer generator takes a Flex lexer specification and generates a faster C++ lexer. The C++ lexer class is saved in clean source code that is easy to use and understand. This class is then compiled and linked with the RE/flex library to produce a scanner:
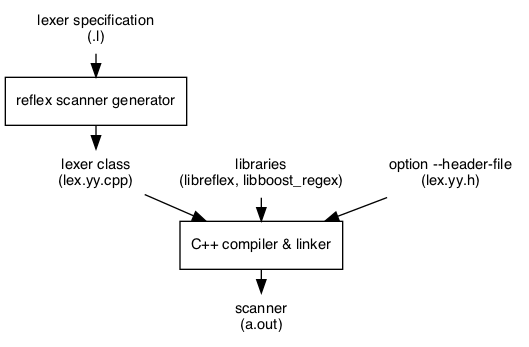
The generated scanner may be a stand-alone application or be part of a larger program, such as a compiler that tokenizes the input:
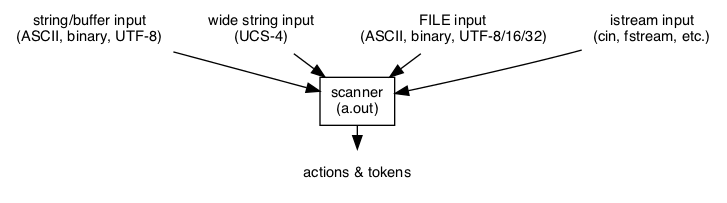
A smart input class is used by the scanner to process diverse input sources, including UTF-8/16/32 files, streams, strings, and memory. The generated scanner executes actions, typically to produce tokens for a parser. The actions are triggered by matching patterns to the input as specified in the lexer specification.
What is new and noteworthy?
RE/flex supports Unicode, indent/nodent/dedent anchors, lazy quantifiers, word boundaries, and more. RE/flex also offers performance tuning with the built-in performance analyzer. There are also multiple regex engines to choose from for the generated scanner: the RE/flex matcher, the Boost.Regex library or PCRE2. The RE/flex matcher runs in direct code as a super fast deterministic finite state machine or as a deterministic finite state machine table, depending on options selected. The Boost.Regex library offers a richer regex syntax but uses a slower non-deterministic finite state machine to match input.
See also

Pursuing
Perfection