|
RE/flex user guide
updated Sun May 17 2026 by Robert van Engelen
|
|
RE/flex user guide
updated Sun May 17 2026 by Robert van Engelen
|
"The asteroid to kill this dinosaur is still in orbit." – Lex Manual
"Reflex: a thing that is determined by and reproduces the essential features or qualities of something else." – Oxford Dictionary
Yet another high-performance C++ regular expression (RE) library and a lexical analyzer generator like Flex.
However, RE/flex also includes and supports several regex engines under the same uniform C++ class API, namely the RE/flex high-performance regex library, the RE/flex fuzzy regex library, the PCRE2 library, the Boost.Regex library, and std::regex.
This uniform API makes it trivial to perform pattern matching on files, streams, strings, wide strings, and memory, using any one of these regex libraries. File input is internally buffered in a window so that very large files can be searched. Input from UTF-16 or UTF-32 formatted files is automatically normalized to UTF-8 to apply UTF-8 Unicode regex pattern matching.
For performance, the RE/flex regex engine internally builds finite state machines in VM opcode or in efficient direct C++ code to scan and search input quick. SIMD (SSE2/AVX2/AVX512/NEON/AArch64) acceleration is used when available to speed up searching using novel pattern match prediction methods.
The RE/flex lexical analyzer generator extends Flex++ with Unicode support and many new useful features, such as regex indentation anchors, regex lazy quantifiers, regex word boundaries, methods for error reporting and recovery, and new options to simplify integration with Bison and other parsers.
The RE/flex lexical analyzer generator does all the heavy-lifting to make it easier to integrate advanced tokenizers with Bison and other parsers. It generates the necessary gluing code depending on the type of Bison parser used, such as the more advanced "Bison complete parsers".
In a nutshell, the RE/flex lexical analyzer generator
RE/flex includes usability improvements over Flex++, such as:
yypush_buffer_state saves the scanner state (line, column, and indentation positions), not just the input buffer;str() and wstr() to obtain the (wide) string match, line() and wline() to obtain the current (wide) line for error reporting.Rule patterns in a lexer specification are converted by the reflex tool to efficient deterministic finite state machines in direct code (option −−fast or in opcode tables −−full. Other regex engines to choose from include PCRE2 and Boost.Regex for Perl and POSIX matching modes. UTF-8/16/32 file input normalization for Unicode pattern matching is performed automatically. Other encodings can be programmatically specified with minimal codeing. Therefore, RE/flex scanners can work on any type of input.
RE/flex incorporates proper object-oriented design principles and does not rely on macros and globals as Flex does. Macros and globals are added to the source code generated by reflex only when option −−flex is specified. A RE/flex scanner is a generated class derived from a base lexer class template, with its matcher engine defined as a template parameter.
RE/flex is compatible with Lex/Flex and Bison/Yacc with options −−flex and −−bison, respectively. Option −−yy forces basic, no-frills Lex POSIX compliance of the lexer input (but with C++ output). RE/flex also offers specific options to seamlessly integrate Bison bridge, Bison locations, Bison C++, Bison complete, and reentrant parsers.
In this document we refer to a regex as a shorthand for regular expression, However, a "regular expression" refers to the formal concept of regular languages, wheras regex often refers to backtracking-based regex matching that Perl introduced. Both concepts are applicable to RE/flex patterns.
In summary, RE/flex is really several things combined into one package:
std::regex libraries for matching, seaching, splitting and scanning of input, with input from (wide) strings, files, and streams of potentially unlimited length.The typographical conventions used by this document are:
Courier denotes C and C++ source code.Courier denotes lexer specifications and file names.Courier denotes commands and command or program output displayed in a terminal window.Lex, Flex and variants are powerful scanner generators that generate scanners (a.k.a. lexical analyzers and lexers) from lexer specifications. The lexer specifications define patterns with user-defined actions that are executed when their patterns match the input stream. The scanner repeatedly matches patterns and triggers these actions until the end of the input stream is reached.
Both Lex and Flex are popular to develop tokenizers in which the user-defined actions emit or return a token when the corresponding pattern matches. These tokenizers are typically implemented to scan and tokenize the source code for a compiler or an interpreter of a programming language. The regular expression patterns in a tokenizer define the make-up of identifiers, constants, keywords, punctuation, and to skip over white space in the source code that is scanned.
Consider for example the following patterns and associated actions defined in a lexer specification:
When the tokenizer matches a pattern, the corresponding action is invoked. The example above returns tokens to the compiler's parser, which repeatedly invokes the tokenizer for more tokens until the tokenizer reaches the end of the input. The tokenizer returns zero (0) when the end of the input is reached.
Lex and Flex have remained relatively stable (inert) tools while the demand has increased for tokenizing Unicode texts encoded in common wide character formats such as UTF-8, UTF-16, and UTF-32. Also the regular expression syntax in Flex/Lex is limited compared to modern regex syntax. Flex has no support for Unicode patterns, no lazy repetitions, no word boundary anchors, no indentation matching with indent or dedent anchors, and a very limited collection of meta escapes to choose from. To make things even more interesting, it is a challenge to write lexer specifications that avoid the "greedy trap" of POSIX matching.
Flex/Lex scanners use POSIX pattern matching, meaning that the leftmost longest match is returned (among a set of patterns that match the same input). Because POSIX matchers produce the longest match for any given input text, we should be careful when using patterns with "greedy" repetitions (X*, X+ etc.) because our pattern may gobble up more input than intended. We end up falling into the "greedy trap".
To illustrate this trap consider matching HTML comments <!−− ... −−> with the pattern <!−−.*−−>. The problem is that the repetition X* is greedy and the .*−−> pattern matches everything until the last −−> while moving over −−> that are between the <!−− and the last −−>.
. normally does not match newline \n in Flex/Lex patterns, unless we use dot-all mode that is sometimes confusingly called "single line mode".We can use much more complex patterns such as <!−−([^−]|−[^−]|−−+[^−>])*−*−−> just to match comments in HTML, by ensuring the pattern ends at the first match of a −−> in the input and not at the very last −−> in the input. The POSIX leftmost longest match can be surprisingly effective in rendering our tokenizer into works of ASCII art!
We may claim our intricate pattern trophies as high achievements to the project team, but our team will quickly point out that a regex <!−−.*?−−> suffices to match HTML comments with the lazy repetition X*? construct, also known as a non-greedy repeat. The ? is a lazy quantifier that modifies the behavior of the X*? repeat to match only X repeatedly if the rest of the pattern does not match. Therefore, the regex <!−−.*?−−> matches HTML comments and nothing more.
But Flex/Lex does not permit us to be lazy!
Not surprising, even the Flex manual shows ad-hoc code rather than a pattern to scan over C/C++ source code input to match multiline comments that start with a /* and end with the first occurrence of a */. The Flex manual recommends:
Another argument to use this code with Flex is that the internal Flex buffer is limited to 16K. By contrast, RE/flex buffers are dynamically resized and will never run out of buffer space to accept long matches.
Workarounds such as these are not necessary with RE/flex. The RE/flex scanners use regex libraries with expressive pattern syntax. We can use lazy repetition to write a regex pattern for multiline comments as follows:
Most regex libraries support syntaxes and features that we have come to rely on for pattern matching. A regex with lazy quantifiers can be much easier to read and comprehend compared to a greedy variant. Most regex libraries that support lazy quantifiers run in Perl mode, using backtracking over the input. Scanners use POSIX mode matching, meaning that the leftmost longest match is found. The difference is important as we saw earlier and even more so when we consider the problems with Perl mode matching when specifying patterns to tokenize input, as we will explain next.
Consider the lexer specification example shown earlier. Suppose the input text to tokenize is iflag = 1. In POSIX mode we return ASCII_IDENTIFIER for the name iflag, OP_ASSIGN for =, and NUMBER for 1. In Perl mode, we find that iflag matches if and the rest of the name is not consumed, which gives KEYWORD_IF for if, ASCII_IDENTIFIER for lag, OP_ASSIGN for =, and a NUMBER for 1. Perl mode matching greedely returns leftmost matches.
Using Perl mode in a scanner requires all overlapping patterns to be defined in a lexer specification such that all longest matching patterns are defined first to ensure longest matches. By contrast, POSIX mode is declarative and allows you to define the patterns in the specification in any order. Perhaps the only ordering constraint on patterns is for patterns that match the same input, such such as matching the keyword if in the example: KEYWORD_IF must be matched before ASCII_IDENTIFIER.
For this reason, RE/flex scanners use a regex library in POSIX mode by default.
In summary:
−−bison generates a scanner compatible with Bison. RE/flex also offers options to integrate Bison bridge, Bison locations, Bison complete, and reentrant parsers.The RE/flex scanner generator section has more details on the RE/flex scanner generator tool.
In the next part of this manual, we will take a quick look at the RE/flex regex API that can be used as a stand-alone library for matching, searching, scanning and splitting input from strings, files and streams in regular C++ applications (i.e. applications that are not necessarily tokenizers for compilers).
RE/flex defines a single uniform C++ base class API for all regex libraries it includes and supports, namely the high-performance RE/flex regex engine, the RE/flex fuzzy matching engine, Boost.Regex, PCRE2, and C++11 std::regex:
| Engine | Header file to include | C++ matcher classes |
|---|---|---|
| RE/flex regex | reflex/matcher.h | reflex::Matcher |
| RE/flex regex | reflex/fuzzymatcher.h | reflex::FuzzyMatcher |
| PCRE2 | reflex/pcre2matcher.h | reflex::PCRE2Matcher, reflex::PCRE2UTFMatcher |
| Boost.Regex | reflex/boostmatcher.h | reflex::BoostMatcher, reflex::BoostPerlMatcher, reflex::BoostPosixMatcher |
| std::regex | reflex/stdmatcher.h | reflex::StdMatcher, reflex::StdEcmaMatcher, reflex::StdPosixMatcher |
The RE/flex reflex::Matcher class compiles regex patterns to efficient non-backtracking deterministic finite state machines (FSM) when instantiated. These deterministic finite automata (DFA) representations speed up matching considerably, at the cost of the initial FSM construction (see further below for hints on how to avoid this run-time overhead). RE/flex matchers use POSIX mode matching, see POSIX versus Perl matching for details.
The RE/flex reflex::FuzzyMatcher class derived from reflex::Matcher supports the same features as the reflex::Matcher class but performs approximate regex pattern matching. The constructor accepts an optional second parameter that specifies the "edit distance" for approximate matching. Pattern search is not as efficient as the reflex::Matcher class that uses SIMD acceleration to speed up search for the find() method.
The reflex::PCRE2Matcher and reflex::PCRE2UTFMatcher classes are for efficient Perl mode matching with PCRE2 using JIT (just-in-time compilation), where the latter uses native PCRE2 Unicode matching with PCRE2_UTF+PCRE2_UCP. The PCRE2 matchers use JIT optimizations to speed up matching, which comes at a cost of extra processing when the matcher is instantiated. The benefit outweighs the cost when many matches are processed.
The reflex::BoostMatcher, reflex::BoostPerlMatcher, and reflex::BoostPosixMatcher classes are for default mode, Perl mode, and POSIX mode matching using the Boost Regex library, respectively.
C++11 std::regex supports ECMAScript and AWK POSIX syntax with the StdMatcher (or StdEcmaMatcher) and reflex::StdPosixMatcher classes respectively. The std::regex syntax is therefore a lot more limited compared to PCRE2, Boost.Regex, and RE/flex. These regex matchers are considerably slower compared to the other matchers.
The RE/flex regex common interface API is implemented in an abstract base class template reflex::AbstractMatcher from which all regex matcher engine classes are derived. This regex API offers a single uniform interface. This interface is used in the generated scanner. You can also use this uniform API in your C++ application for pattern matching with any of the regex libraries without having to use library-specific API calls to do so.
The RE/flex base class reflex::AbstractMatcher offers four typical operations to match, search, scan, and split input with regex patterns:
| Method | Result |
|---|---|
matches() | returns nonzero if the input from begin to end matches |
find() | search the given input and return nonzero if a match was found |
scan() | return nonzero if input at current position matches partially |
split() | return nonzero for a split of the input at the next match |
These methods return a nonzero value for a match, meaning the size_t reflex::AbstractMatcher::accept() value that identifies the regex group pattern that matched. These methods are repeatable where the last three in the list return additional matches when found.
For example, to check if a string is a valid date using Boost.Regex:
We can perform exactly the same check with PCRE2 instead of Boost.Regex:
Swapping regex libraries like this is trivial. The JIT-optimized PCRE2 matcher is better suited when many matches are performed on multiple inputs, not just one match as shown above. PCRE2 also fully supports "partial matching" which RE/flex internally uses so that large input such as from large files is searched incrementally with a sliding window.
For example, to search a string for all words matching the pattern \w+:
When executed this code prints:
Found How Found now Found brown Found cow
Changing the input for this example is trivial too, using the reflex::Input class. Say we want to search for words in a file:
Sometimes we may need a regex converter when we want to use a regex feature that the regex library we use does not support.
If we want to match Unicode words, \w+ should be converted to a Unicode pattern, here we convert the pattern for matching with the high-performance RE/flex regex library:
Conversion to support Unicode patterns is necessary for all matchers except for the reflex::PCRE2UTFMatcher, since matchers operate in non-Unicode mode by default to match bytes, not wide characters. We will come back again to converters later.
When executed this code prints:
Found Höw Found nöw Found bröwn Found cöw
The same code and results are produced with reflex::PCRE2Matcher defined in reflex/pcre2matcher.h. For the following examples we will use Boost.Regex or PCRE2, which may be used interchangeably.
The scan method is similar to the find method, but scan matches only from the current position in the input. It fails when no partial match was possible at the current position. Repeatedly scanning an input source means that matches must be continuous, otherwise scan returns zero (no match).
The split method is roughly the inverse of the find method and returns text located between matches. For example using non-word matching \W+:
When executed this code prints:
Found How Found now Found brown Found cow Found
Note that split also returns the (possibly empty) remaining text after the last match, as you can see in the output above: the last split with \W+ returns an empty string, which is the remaining input after the period in the sentence.
The find(), scan() and split() methods return a nonzero *"accept"* value, which corresponds to the regex group captured, or the methods return zero if no match was found. The methods return 1 for a match when no groups are used. The split() method has a special case. It returns the value reflex::PCRE2Matcher::Const::EMPTY (and so does any other matcher) when a match was made at the end of the input and an empty string was split, as is the case of the last split() match in the example above.
Another example:
When executed this code prints:
word space word space word space word other
The regex engines currently available as classes in the reflex namespace are:
| Class | Mode | Engine | Performance |
|---|---|---|---|
reflex::Matcher | POSIX | RE/flex | FSM, no backtracking |
reflex::FuzzyMatcher | POSIX | RE/flex | FSM, minimal backtracking (fuzzy) |
reflex::PCRE2Matcher | Perl | PCRE2 | JIT-optimized backtracking |
reflex::PCRE2UTFMatcher | Perl | PCRE2 UTF+UPC | JIT-optimized backtracking |
reflex::BoostMatcher | Perl | Boost.Regex | backtracking |
reflex::BoostPerlMatcher | Perl | Boost.Regex | backtracking |
reflex::BoostPosixMatcher | POSIX | Boost.Regex | backtracking |
reflex::StdMatcher | ECMA | std::regex | backtracking |
reflex::StdEcmaMatcher | ECMA | std::regex | backtracking |
reflex::StdPosixMatcher | POSIX | std::regex | backtracking |
The RE/flex regex engine uses a deterministic finite state machine (FSM) to get the best performance when matching. However, constructing a FSM adds overhead. This matcher is better suitable for searching long texts. The FSM construction overhead can be eliminated by pre-converting the regex to C++ code tables ahead of time as we will see shortly. RE/flex fuzzy matching may require minimal backtracking for approximate pattern matches to find a minimal, but not necessarily optimal (!), "edit distance" from an exact match.
The PCRE2 engines use Perl mode matching. PCRE2 also offers POSIX mode matching with pcre2_dfa_match(). However, group captures are not supported in this mode. Therefore, no PCRE2 POSIX mode class is included as a choice. JIT optimizations speed up matching. However, this comes at a cost of extra processing when the PCRE2 matcher class is instantiated.
The Boost.Regex engines normally use Perl mode matching. We added a POSIX mode Boost.Regex engine class for the RE/flex scanner generator. Scanners typically use POSIX mode matching. See POSIX versus Perl matching for more information.
The Boost.Regex engines are all initialized with match_not_dot_newline, which disables dotall matching as the default setting. Dotall can be re-enabled with the (?s) regex mode modifier. This is done for compatibility with scanners.
A matcher may be applied to strings and wide strings, such as std::string and std::wstring, char* and wchar_t*. Wide strings are converted to UTF-8 to enable matching with regular expressions that contain Unicode patterns.
To match Unicode patterns with regex library engines that are 8-bit based or do not support Unicode, we want to convert your regex string first before we use it with a regex matcher engine:
This converts the Unicode character classes to UTF-8 for matching with an 8-bit regex engine. The convert static method differs per matcher class. An error reflex::regex_error is thrown as an exception if conversion was not possible, which is unlikely, or if the regex is syntactically incorrect.
Conversion is fast (it runs in linear time in the size of the regex), but it is not without some overhead. We should make the converted regex patterns static whenever possible, as shown above, to eliminate the cost of repeated conversions and pattern constructions.
A reflex::Pattern object is immutable (it stores a constant table) and may be shared among threads.
Use convert with option reflex::convert_flag::unicode to change the meaning of . (dot), \w, \s, \l, \u, \W, \S, \L, \U character classes.
File contents are streamed into the matcher using partial matching algorithms and matching happens immediately. This means that the input does not need to be loaded as a whole into memory. This supports interactive matching, i.e. matching the input from a console:
Interactive input is slow to consume due to non-buffered input.
We can also pattern match text from FILE descriptors. The additional benefit of using FILE descriptors is the automatic decoding of UTF-16/32 input to UTF-8 by the reflex::Input class that manages input sources and their state.
For example, pattern matching the content of "cows.txt" that may use UTF-8, 16, or 32 encodings:
The find, scan, and split methods are also implemented as input iterators that apply filtering tokenization, and splitting:
| Iterator range | Acts as a | Iterates over |
|---|---|---|
find.begin()...find.end() | filter | all matches |
scan.begin()...scan.end() | tokenizer | continuous matches |
split.begin()...split.end() | splitter | text between matches |
The type reflex::AbstractMatcher::Operation is a functor that defines find, scan, and split. The functor operation returns true upon success. The use of an iterator is simply supported by invoking begin() and end() methods of the functor, which return reflex::AbstractMatcher::iterator. Likewise, there are also cbegin() and cend() methods that return a const_iterator.
We can use these RE/flex iterators in C++ for many tasks, including to populate containers by stuffing the iterator's text matches into it:
As a result, the words vector contains "How", "now", "brown", "cow".
Casting a matcher object to std::string is the same as converting text() to a string with std::string(text(), size()), which in the example above is done to construct the words vector. Casting a matcher object to std::wstring is similar, but also converts the UTF-8 text() match to a wide string.
RE/flex iterators are useful in C++11 range-based loops. For example:
When executed this code prints:
Found How Found now Found brown Found cow
And RE/flex iterators are also useful with algorithms and lambdas, for example to compute a histogram of word frequencies:
As a result, the freq array contains 0, 1, 1, and 2.
Casting the matcher object to a size_t returns the group capture index, which is used in the example shown above. We also us it in the example below that is capturing all regex pattern groupings into a vector:
As a result, the vector contains the group captures 3, 1, 3, and 2.
Casting the matcher object to size_t is the same as invoking accept().
This method and other methods may be used to obtain the details of a match:
| Method | Result |
|---|---|
accept() | returns group capture index (or zero if not captured/matched) |
text() | returns const char* to 0-terminated match (ends in \0) |
strview() | returns std::string_view text match (preserves \0s) (C++17) |
str() | returns std::string text match (preserves \0s) |
wstr() | returns std::wstring wide text match (converted from UTF-8) |
chr() | returns first 8-bit char of the text match (str()[0]) |
wchr() | returns first wide char of the text match (wstr()[0]) |
chr_last() | returns last 8-bit char of the text match or 0 when empty |
wchr_last() | returns last wide char of the text match or 0 when empty |
chr_next() | returns next 8-bit char after the text match or EOF at end |
wchr_next() | returns next wide char after the text match or EOF at end |
pair() | returns std::pair<size_t,std::string>(accept(),str()) |
wpair() | returns std::pair<size_t,std::wstring>(accept(),wstr()) |
size() | returns the length of the text match in bytes |
wsize() | returns the length of the match in number of wide characters |
empty() | returns true if the match is empty (size() == 0) |
lines() | returns the number of lines in the text match (>=1) |
columns() | returns the number of columns of the text match (>=0) |
begin() | returns const char* to non-0-terminated text match begin |
end() | returns const char* to non-0-terminated text match end |
rest() | returns const char* to 0-terminated rest of input |
span() | returns const char* to 0-terminated match enlarged to span the line |
line() | returns std::string line with the matched text as a substring |
wline() | returns std::wstring line with the matched text as a substring |
more() | tells the matcher to append the next match (when using scan()) |
less(n) | cuts text() to n bytes and repositions the matcher |
lineno() | returns line number of the match, starting at line 1 |
columno() | returns column number of the match in characters, starting at 0 |
lineno_end() | returns ending line number of the match, starting at line 1 |
columno_end() | returns ending column number of the match, starting at 0 |
bol() | returns const char* to begin of matching line (not 0-terminated) |
border() | returns the byte offset from the start of the line of the match |
first() | returns input position of the first character of the match |
last() | returns input position + 1 of the last character of the match |
at_bol() | true if matcher reached the begin of a new line \n |
at_bob() | true if matcher is at the begin of input and no input consumed |
at_end() | true if matcher is at the end of input |
[0] | operator returns std::pair<const char*,size_t>(begin(),size()) |
[n] | operator returns n'th capture std::pair<const char*,size_t> |
For a detailed explanation of these methods, see Properties of a match.
The operator[n] takes the group number n and returns the n'th group capture match as a pair with a const char* pointer to the group-matching text and the size of the matched text in bytes. Because the pointer points to a string that is not 0-terminated, use the size to determine the matching part.
The pointer is NULL when the group capture has no match.
For example:
When executed this code prints:
name: cow, number: 123
text() method returns the match by pointing to the const char* string that is stored in an internal buffer. This pointer should not be used after matching continues and when the matcher object is deallocated. To retain the text() value we recommend to use the str() method that returns a copy of text(). Likewise, the strview() method returns the same text() pointer and should not be used after matching continues.operator[] method returns a pair with the match info of the n'th group, which is a non-0-terminated const char* pointer (or NULL) and its size in bytes of the captured match. The string should not be used after matching continues.reflex::Matcher class, the accept() method returns the accepted pattern among the alternations in the regex that are specified only at the top level in the regex. For example, the regex "(a(b)c)|([A-Z])" has two groups, because only the outer top-level groups are recognized. Because groups are specified at the top level only, the grouping parenthesis are optional. We can simplify the regex to "a(b)c|[A-Z]" and still capture the two patterns.The following methods may be used to manipulate the input stream directly:
| Method | Result |
|---|---|
input() | returns next 8-bit char from the input, matcher then skips it |
winput() | returns next wide character from the input, matcher skips it |
unput(c) | put 8-bit char c back unto the stream, matcher then takes it |
wunput(c) | put (wide) char c back unto the stream, matcher then takes it |
peek() | returns next 8-bit char from the input without consuming it |
skip(c) | skip input until character c (char or wchar_t) is consumed |
skip(s) | skip input until UTF-8 string s is consumed |
rest() | returns the remaining input as a 0-terminated char* string |
The input(), winput(), and peek() methods return a non-negative character code and EOF (-1) when the end of input is reached.
To initialize a matcher for interactive use, to assign a new input source or to change its pattern, use the following methods:
| Method | Result |
|---|---|
input(i) | set input to reflex::Input i (string, stream, or FILE*) |
pattern(p) | set pattern reflex::Pattern, boost::regex, or a string p |
has_pattern() | true if the matcher has a pattern assigned to it |
own_pattern() | true if the matcher has a pattern to manage and delete |
pattern() | a reference to the pattern object |
buffer() | buffer all input at once, returns true if successful |
buffer(n) | set the buffer window size to n bytes to read in chunks |
buffer(b, n) | use buffer of n bytes at address b with to a string of n-1 bytes (zero copy) |
interactive() | set buffer size to 1 for console-based (TTY) input |
flush() | flush the remaining input from the internal buffer |
reset() | resets the matcher, restarting it from the remaining input |
reset(o) | resets the matcher with new options string o ("A?N?T?") |
A reflex::Input object represents the source of input for a matcher, which is either a file FILE*, or a string (with UTF-8 character data) of const char* or std::string type, or a stream pointer std::istream*. The reflex::Input object is implicitly constructed from one of these input sources, for example:
The entire input is buffered in a matcher with buffer(), or is read piecemeal with buffer(n), or is read interactively with interactive(). These methods should be used after setting the input source. Reading a stream with buffering all input data at once is done with the >> operator as a shortcut:
Zero-copy overhead is achieved by specifying buffer(b, n) to read n-1 bytes located at address b for in-place matching, where bytes b[0...n] are possibly modified by the matcher:
buffer(b, n) specifies n-1 bytes at address b. The length n should include one extra byte that can be modified.text() or rest() are used. Only unput(c), wunput(), text(), rest(), and span() modify the buffer contents, because these functions require an extra byte at the end of the buffer to make the strings returned by these methods 0-terminated. This means that we can specify read-only memory of n bytes located at address b by using buffer(b, n+1) safely as long as we do not use unput(), unput(), text(), rest(), and span(), for example to search read-only mmap(2) PROT_READ memory.So far we explained how to use reflex::PCRE2Matcher and reflex::BoostMatcher for pattern matching. We can also use the RE/flex reflex::Matcher class for pattern matching. The API is exactly the same. The reflex::Matcher class uses reflex::Pattern, which internally represents an efficient finite state machine that is compiled from a regex. These state machines are used for fast matching.
The construction of deterministic finite state machines (FSMs) is optimized but can take some time and therefore adds overhead before matching can start. This FSM construction should not be executed repeatedly if it can be avoided. So we recommend to construct static pattern objects to create the FSMs only once:
A reflex::Pattern object is immutable (it stores a constant table) and may be shared among threads.
The RE/flex matcher only supports POSIX mode matching and does not support Perl mode matching. See POSIX versus Perl matching for more information.
The RE/flex reflex::Pattern class has several options that control the regex. Options and modes for the regex are set as a string, for example:
The f=graph.gv option emits a Graphviz .gv file that can be visually rendered with the open source Graphviz dot tool by converting the deterministic finite state machine (FSM) to PDF, PNG, or other formats:
The f=machine.cpp option emits opcode tables for the FSM to match regular expressions efficiently. The FSM matcher engine runs as a virtual machine to execute opcodes without backtracking. In this case we get the following FSM table with eleven code words:
Option o may be used with f=machine.cpp to emit optimized native C++ code for the FSM that gnerally runs faster than running the virtual machine on opcode tables:
In addition, a search predictor table is generated that must be used to support and accelerate search when the reflex::Matcher::find or reflex::FuzzyMatcher::find method is used. This table MUST be passed to the reflex::Pattern constructor. This is necessary to support find(). Other matcher methods do not require this table. The benefit is that this approach omits the FSM construction overhead that would take place at runtime. For example:
The tables are used directly in your application. The constructed static reflex::Pattern is thread-safe to share.
The RE/flex reflex::Pattern construction options are given as a string:
| Option | Effect |
|---|---|
b | bracket lists are parsed without converting escapes |
e=c; | redefine the escape character |
f=file.cpp; | save finite state machine code to file.cpp |
f=file.gv; | save deterministic finite state machine to file.gv |
i | case-insensitive matching, same as (?i)X |
m | multiline mode, same as (?m)X |
n=name; | use reflex_code_name for the machine (instead of FSM) |
o | only with option f: generate optimized FSM native C++ code |
q | Flex/Lex-style quotations "..." equal \Q...\E, same as (?q)X |
r | throw regex syntax error exceptions, otherwise ignore errors |
s | dot matches all (aka. single line mode), same as (?s)X |
x | free space mode with inline comments, same as (?x)X |
w | display regex syntax errors before raising them as exceptions |
For example, reflex::Pattern pattern(pattern, "isr") enables case-insensitive dot-all matching with syntax errors thrown as reflex::regex_error types of exceptions. By default, the reflex::Pattern constructor solely throws the reflex::regex_error::exceeds_length and reflex::regex_error::exceeds_limits exceptions and silently ignores syntax errors, see The reflex::Pattern class .
In summary:
FILE* data, strings and wide strings, buffers, and streaming data.The RE/flex regex library section has more information about the RE/flex regex library.
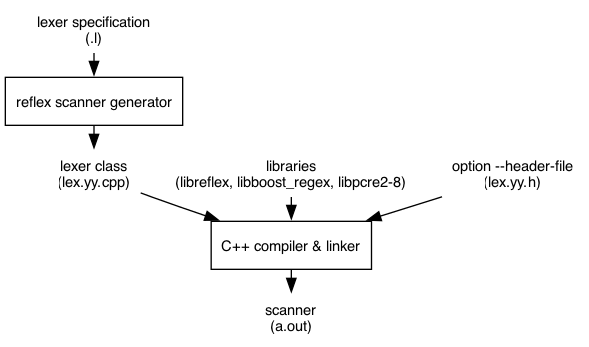
The RE/flex scanner generator reflex takes a lexer specification and generates a regex-based C++ lexer class that is saved to lex.yy.cpp, or saved to the file we specified by the -o command-line option. This file is then compiled and linked with option -lreflex (and optionally -lboost_regex if we use Boost.Regex for matching or -lpcre2-8 if we use PCRE2 for matching) to produce a scanner:
reflex lexerspec.l c++ lex.yy.cpp -lreflex
We use option −−header-file to generate lex.yy.h to include in the source code of your lexer application:
reflex −−header-file=lexerspec.l c++ mylexer.cpp lex.yy.cpp -lreflex
If libreflex was not installed then linking with -lreflex fails. See Undefined symbols and link errors on how to resolve this.
The scanner can be a stand-alone application based on lex.yy.cpp alone, or be part of a larger program, such as a compiler:
The RE/flex-generated scanners use the RE/flex regex library API for pattern matching. The RE/flex regex library API is defined by the abstract class reflex::AbstractMatcher.
There are three regex matching engines to choose from for the generated scanner: the Boost.Regex library, the PCRE2 linrary, or the built-in RE/flex POSIX matcher engine. In any case, the libreflex library should be linked. The libboost_regex library or the libpcre2-8 library should only be linked when the Boost.Regex or PCRE2 engines are used for matching, respectively.
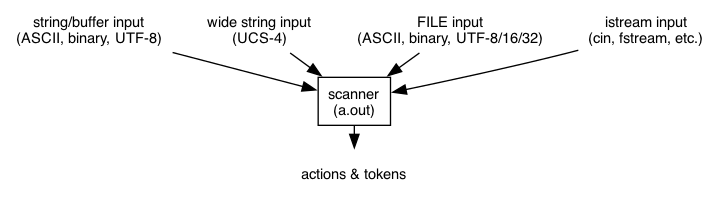
The input class reflex::Input of the libreflex library manages input from strings, wide strings, streams, and data from FILE descriptors. File data may be encoded in ASCII, binary or in UTF-8/16/32. UTF-16/32 is automatically decoded and converted to UTF-8 for UTF-8-based regex matching:
The generated scanner executes actions (typically to produce tokens for a parser). The actions are triggered by matching patterns to the input.
The reflex command takes a lexer specification from standard input or from the specified file (usually with extension .l, .ll, .l++, .lxx, or .lpp) and generates a C++ scanner class that is saved to the lex.yy.cpp source code file.
The lex.yy.cpp source code output is structured in sections that are clean, readable, and reusable.
Use reflex option −−header-file to generate lex.yy.h to include in the source code of your application:
reflex −−header-file=lexerspec.l
The reflex command accepts −−flex and −−bison options for compatibility with Flex and Bison/Yacc, respectively. These options allow reflex to be used as a replacement of the classic Flex and Lex tools:
reflex −−flex −−bison lexerspec.l
The first option −−flex specifies that lexerspec.l is a classic Flex/Lex specification with yytext or YYText() and the usual "yy" variables and functions.
The second option −−bison generates a scanner class and the usual global "yy" variables and functions such as yytext, yyleng, yylineno, and yylex() for compatibility with non-reentrant Bison parsers. See Interfacing with Bison/Yacc for more details on Bison parsers that are reentrant and/or use bison-bridge and bison-locations options. For Bison 3.0 C++ parsers, use −−bison-cc and optionally −−bison-locations.
Option −−yy enables both −−flex and −−bison and maximizes compatibility with Lex/Flex by generating the global yyin and yyout variables and global yy functions. Otherwise, yyin points to a reflex::Input object for advanced input handling, which is more powerful than the traditional FILE* type yyin.
To control the output of the reflex scanner generator use the command-line options described in the next subsections. These options can also be specified in the lexer specification with %option or %o for short, for example:
The above is equivalent to the −−flex, −−bison, and −−graphs-file=mygraph.gv command-line options.
Multiple options can be grouped on a single line:
An option parameter name may contain hyphens (-), dots (.), and double colons (::). Flex always requires quotes with option parameters, but RE/flex does not require quotes except when special characters are used, for example:
Quotes (") and backslashes (\) should be escaped in an option parameter:
Shorter forms may be used by omitting %o altogether, requiring each option to be specified on a separate line:
Options that affect the regular expressions such as %option unicode and %option dotall should be specified before any regular expressions are defined and used in the specification.
The scanner code generated by reflex defines options as macros REFLEX_OPTION_name with a value of true when the option is enabled or with the value that is assigned to the option. This allows your program code to check and use RE/flex options. For example, the lexer class name is REFLEX_OPTION_lexer when the lexer class name is redefined with command-line option −−lexer=NAME or in the lexer specification with %option lexer=NAME.
−+, −−flexThis option generates a yyFlexLexer scanner class that is compatible with the Flex-generated yyFlexLexer scanner class (assuming Flex with option −+ for C++). The generated yyFlexLexer class has the usual yytext and other "yy" variables and functions, as defined by the Flex specification standard. Without this option, RE/flex actions should be used that are lexer class methods such as text(), echo() and also the lexer's matcher methods, such as matcher().more(), see The rules section for more details.
-a, −−dotallThis option makes dot (.) in patterns match newline. Normally dot matches a single character except a newline (\n ASCII 0x0A).
-B, −−batchThis option generates a batch input scanner that reads the entire input all at once when possible. This scanner is fast, but consumes more memory depending on the input data size. An option argument may be specified to initialize the buffer size to support incremental scanning by reading chunks of input, for example −−batch=1024 reads the input in 1024 byte chunks.
-f, −−full(RE/flex matcher only). This option adds the FSM to the generated code as a static opcode table, thus generating the scanner in full. FSM construction overhead is eliminated when the scanner is initialized, resulting in a scanner that starts scanning the input immediately. This option has no effect when option −−fast is specified.
-F, −−fast(RE/flex matcher only). This option adds the FSM to the generated code as optimized native C++ code. FSM construction overhead is eliminated when the scanner is initialized, resulting in a scanner that starts scanning the input immediately. The generated code takes more space compared to the −−full option.
-S, −−findThis option generates a search engine to find pattern matches to invoke actions corresponding to matching patterns. Unmatched input is ignored. By contrast, option -s (or −−nodefault) produces an error when non-matching input is found.
-i, −−case-insensitiveThis option ignores case in patterns. Patterns match lower and upper case letters in the ASCII range only.
-I, −−interactive, −−always-interactiveThis option generates an interactive scanner and permits console input by sacrificing speed. This optiong is essentially the same as −−batch=1 to consume one character at a time. By contrast, the default buffered input strategy is more efficient.
−−indent and −−noindentThis option enables or disables support for indentation matching with anchors \i, \j, and \k. Indentation matching is enabled by default. Matching speed may be improved by disabling indentation matching, but should only be disabled when none of the indentation anchors is used in any of the patterns.
-m reflex, −−matcher=reflexThis option generates a scanner that uses the RE/flex reflex::Matcher class with a POSIX matcher engine. This is the default matcher for scanning. This option is best for Flex compatibility. This matcher supports lazy quantifiers, Unicode mode, Anchors and boundaries, Indent/nodent/dedent matching, and supports FSM output for visualization with Graphviz.
-m boost, −−matcher=boostThis option generates a scanner that uses the reflex::BoostPosixMatcher class with a Boost.Regex POSIX matcher engine for scanning. The matcher supports Unicode, word boundary anchors, and more, but not lazy quantifiers. Graphviz output is not supported.
-m boost-perl, −−matcher=boost-perlThis option generates a scanner that uses the reflex::BoostPerlMatcher class with a Boost.Regex normal (Perl) matcher engine for scanning. The matching behavior differs from the POSIX leftmost longest rule and results in the first matching rule to be applied instead of the rule that produces the longest match. Graphviz output is not supported.
-m pcre2-perl, −−matcher=pcre2-perlThis option generates a scanner that uses the reflex::PCRE2Matcher class with a PCRE2 (Perl) matcher engine for scanning. The matching behavior differs from the POSIX leftmost longest rule and results in the first matching rule to be applied instead of the rule that produces the longest match. Graphviz output is not supported.
−−pattern=NAMEThis option defines a custom pattern class NAME for the custom matcher specified with option -m.
−−include=FILEThis option defines a custom include FILE.h to include for the custom matcher specified with option -m.
-T N, −−tabs=NThis option sets the tab size to N, where N can be set to 1 (no expansion), 2, 4, or 8. The default tab size is 8. The tab size determines the column position for Indent/nodent/dedent matching and to determine the column position returned by columno(), columno_end(), and the number of columns returned by columns(). It has no effect otherwise. This option assigns the T=N value of the reflex::Matcher constructor options at runtime. The value may be set at runtime with matcher().tabs(N) with N 1, 2, 4, or 8.
-u, −−unicodeThis option makes ., \s, \w, \l, \u, \S, \W, \L, \U match Unicode. Also groups UTF-8 sequences in the regex, such that each UTF-8 encoded character in a regex is properly matched as one wide character.
-x, −−freespaceThis option switches the reflex scanner to free space mode. Regular expressions in free space mode may contain spacing and may be indented to improve readability. All spacing before, within and after regular expressions is ignored. To match a space use " " or [ ], and use \h to match a space or a tab character. Actions in free space mode MUST be placed in { } blocks and user code must be placed in %{ %} blocks. Patterns ending in an escape \ continue on the next line.
-o FILE, −−outfile=FILEThis option saves the scanner to FILE instead of lex.yy.cpp.
-t, −−stdoutThis option writes the scanner to stdout instead of to lex.yy.cpp.
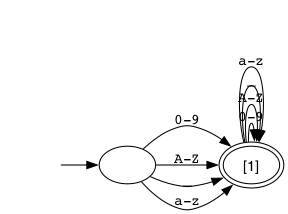
−−graphs-file[=FILE[.gv]](RE/flex matcher only). This option generates a Graphviz file FILE.gv, where FILE is optional. When FILE is omitted the reflex command generates the file reflex.S.gv for each start condition state S defined in the lexer specification. This includes reflex.INITIAL.gv for the INITIAL start condition state. This option can be used to visualize the RE/flex matcher's finite state machine with the Graphviz dot tool. For example:

In case you are curious: the specification for this FSM digraph has two patterns: [1] a pattern to match dollar amounts with the regex \$\d+(\.\d{2})? and [2] the regex .|\n to skip a character and advance to the next match.
−−header-file[=FILE]This option generates a C++ header file FILE that declares the lexer class, in addition to the generated lexer class code, where FILE is optional. When FILE is omitted the reflex command generates lex.yy.h.
−−regexp-file[=FILE[.txt]]This option generates a text file FILE.txt that contains the scanner's regular expression patterns, where FILE is optional. When FILE is omitted the reflex command generates reflex.S.txt for each start condition state S. The regular expression patterns are converted from the lexer specification and translated into valid C++ strings that can be used with a regex library for pattern matching.
−−tables-file[=FILE[.cpp]](RE/flex matcher only). This option generates a C++ file FILE.cpp with the finite state machine in source code form, where FILE is optional. When FILE is omitted the reflex command generates reflex.S.cpp for each start condition state S. This includes the file reflex.INITIAL.cpp for the INITIAL start condition state. When this option is specified in combination with −−full or −−fast, the reflex::Pattern is instantiated with the code table defined in this file. Therefore, when we combine this option with −−full or −−fast then you should compile the generated table file with the scanner. Options −−full and −−fast eliminate the FSM construction overhead when the scanner is initialized.
−−namespace=NAMEThis option places the generated scanner class in the C++ namespace NAME scope, that is NAME::Lexer (and NAME::yyFlexLexer when option −−flex is used). NAME can be a list of nested namespaces of the form NAME1::NAME2::NAME3 ... or by using a dot as in NAME1.NAME2.NAME3 ...
−−lexer=NAMEThis option defines the NAME of the generated scanner class and replaces the default name Lexer (and replaces yyFlexLexer when option −−flex is specified). The scanner class members may be declared within a %class{ } block. The scanner class constructor code may be defined within a %init{ } block. Additional constructor arguments may be declared with %option ctorarg="argument, argument, ..." and initializers with %option ctorinit="initializer, initializer, ...".
−−lex=NAMEThis option defines the NAME of the generated scanner function to replace the function name lex() (and yylex() when option −−flex is specified).
−−params="TYPE NAME, ..."This option defines additional parameters for the lex() scanner function (and yylex() when option −−flex is specified). The function signature is extended to include the comma-separated TYPE NAME parameters. This mechanism replaces Flex YY_DECL, see YY_DECL alternatives.
−−class=NAMEThis option defines the NAME of the user-defined scanner class that should be derived from the generated base Lexer class. Use this option when defining your own scanner class named NAME. You can declare your custom lexer class in the first section of the lexer specification. Because the custom lexer class is user-defined, reflex generates the implementation of the lex() scanner function for this specified class.
−−yyclass=NAMEThis option combines options −−flex and −−class=NAME.
−−mainThis option generates a main function to create a stand-alone scanner that scans data from standard input (using stdin).
-L, −−nolineThis option suppresses the #line directives in the generated scanner code.
-P NAME, −−prefix=NAMEThis option specifies NAME as a prefix for the generated yyFlexLexer class to replace the default yy prefix. Also renames the prefix of yylex(). Generates lex.NAME.cpp file instead of lex.yy.cpp, and generates lex.NAME.h with option −−header-file.
−−nostdinitThis option initializes input to std::cin instead of stdin, if no input was assigned to the scanner. This option also prevents a scanner to automatically read stdin before any other input is assigned, when detecting UTF encodings on standard input. Note that automatic UTF decoding is not supported on std::cin. Use stdin for automatic UTF BOM detection and UTF decoding of standard input streams, not std::cin.
−−bisonThis option generates a scanner that works with Bison parsers, by defining global (i.e. non-thread-safe and non-reentrant) "yy" variables and functions, such as yytext, yyleng, yylineno, and yylex(). See Interfacing with Bison/Yacc for more details. Use option −−noyywrap to remove the dependency on the global yywrap() function. Use option −−bison-locations to support the Bison %locations feature. See also the −−yy option.
−−bison-bridgeThis option generates a scanner that works with Bison pure (reentrant thead-safe) parsers using a Bison bridge for one ore more scanner objects. Combine this option with −−bison-locations to support the Bison %locations feature. See Bison-bridge for more details.
−−bison-ccThis option generates a scanner that works with Bison 3.0 %skeleton "lalr1.cc" C++ parsers that are thread-safe. Combine this option with −−bison-locations to support the Bison %locations grammar. See Bison-cc for more details.
−−bison-cc-namespace=NAMEThis option specifies one or more NAME namespace(s) for the Bison 3.0 %skeleton "lalr1.cc" C++ parser, which is yy by default.
−−bison-cc-parser=NAMEThis option specifies the class NAME of the Bison 3.0 %skeleton "lalr1.cc" C++ parser, which is parser by default.
−−bison-completeThis option generates a ascnner that works with Bison 3.2 C++ complete symbols, specified by %define api.value.type variant and %define api.token.constructor in a Bison grammar file. This option also sets option −−bison-cc and sets −−token-type to the parser's symbol_type, and sets −−token-eof to 0, assuming these options are not specified already. Combine this option with −−bison-locations to support the Bison %locations feature. See Bison-complete for more details.
−−bison-locationsThis option generates a scanner that works with Bison with locations enabled. See Bison-locations for more details.
-R, −−reentrantThis option generates additional Flex-compatible yylex() reentrant scanner functions. RE/flex scanners are always reentrant, assuming that %class variables are used instead of the user declaring global variables. This is a Flex-compatibility option and should only be used with options −−flex and −−bison. With this option enabled, most Flex functions take a yyscan_t scanner as an extra last argument. See Reentrant scanners and also Interfacing with Bison/Yacc .
-y, −−yyThis option enables −−flex and −−bison to generate a scanner that accepts Flex lexer specifications and works with Bison parsers, by defining global (i.e. non-thread-safe and non-reentrant) "yy" variables and functions, such as yyin, yyout, yytext, yyleng, yylineno, and yylex().
−−yywrap and −−noyywrapOption −−yywrap generates a scanner that calls the global int yywrap() function when EOF is reached. This option is only applicable when −−flex is used for compatibility and when −−flex and −−bison are used together, or when −−yy is specified. Wrapping is enabled by default. Use −−noyywrap to disable the dependence on this global function. This option has no effect for C++ lexer classes, which have a virtual int wrap() (or yywrap() with option −−flex) method that may be overridden.
−−exception=VALUEThis option defines the exception to be thrown by the generated scanner's default rule when no rule matches the input. This option generates a default rule with action throw VALUE and replaces the standard default rule that echoes all unmatched input text when no rule matches. This option has no effect when option -S (or −−find) is specified. See also option -s (or −−nodefault). Care should be taken to advance the input explicitly in the exception handler, for example by calling lexer.matcher().winput() when lexer.size() is zero.
−−token-type=NAMEThis option specifies the type of the token values returned by lex() and yylex(). The type of the values returned by lex() and yylex() is int by default. This option may be used to specify an alternate token type. Option −−bison-complete automatically defines the appropriate token type symbol_type depending the the parameters specified with options −−bison-cc-namespace and −−bison-cc-parser.
−−token-eof=VALUEThis option specifies the value returned by lex() and yylex() when the end of the input is reached and when no <<EOF>> rule is present. By default, a default-constructed token type value is returned when the end of input is reached. For int this is int(), which is zero. By setting −−token-type=EOF the value EOF is returned, for example.
-d, −−debugThis option enables debug mode in the generated scanner. Running the scanner produces debug messages on std::cerr standard error and the debug() function returns nonzero. To temporarily turn off debug messages, use set_debug(0) in your action code. To turn debug messages back on, use set_debug(1). The set_debug() and debug() methods are virtual methods of the lexer class, so you can override their behavior in a derived lexer class. This option also enables assertions that check for internal errors. See Debugging and profiling for details.
-D [START:]FILE, --do=[START:]FILEThis option immediately tests the lexer rule patterns against the specified input FILE. No scanner code is generated. The debug messages output by this option are identical to option -d messages output by the generated and compiled scanner when executed on the input FILE. Only a single start condition state is active and never changed during scanning, because the scanner's lexer actions are not actually executed. The start condition is 0 (or INITIAL) by default.
-p, −−perf-reportThis option enables the collection and reporting of statistics by the generated scanner. The scanner reports the performance statistics on std::cerr when EOF is reached. If your scanner does not reach EOF, then invoke the lexer's perf_report() method explicitly in your code. Invoking this method also resets the statistics and timers, meaning that this method will report the statistics collected since it was last called. See Debugging and profiling for details.
-s, −−nodefaultThis option suppresses the default rule that echoes all unmatched input text when no rule matches. With the −−flex option, the scanner reports "scanner
jammed" when no rule matches by calling yyFlexLexer::LexerError("scanner
jammed"). Without the −−flex and −−debug options, a std::runtime exception is raised by invoking AbstractLexer::lexer_error("scanner jammed"). To throw a custom exception instead, use option −−exception or override the virtual method lexer_error in a derived lexer class. The virtual methods LexerError and lexer_error may be redefined by a user-specified derived lexer class, see Inheriting Lexer/yyFlexLexer . Without the −−flex option, but with the −−debug option, the default rule is suppressed without invoking lexer_error to raise an exception. See also options −−exception=VALUE and -S (or −−find).
-v, −−verboseThis option displays a summary of scanner statistics.
-w, −−nowarnThis option disables warnings.
-h, −−helpThis option displays helpful information about reflex.
-V, −−versionThis option displays the current reflex release version.
−−yylineno, −−yymoreThese options are enabled by default and have no effect.
A lexer specification consists of three sections that are divided by %% delimiters that are placed on a single line:
The definitions section is used to define named regex patterns, to set options for the scanner, and for including C++ declarations.
The rules section is the main workhorse of the scanner and consists of patterns and actions, where patterns may use named regex patterns that are defined in The definitions section. The actions are executed when patterns match. For example, the following lexer specification replaces all occurrences of cow by chick in the input to the scanner:
The default rule is to echo any input character that is read from input that does not match a rule in The rules section, so all other text is faithfully reproduced by this simple scanner example.
Because the pattern cow also matches words partly we get chicks for cows. But we also get badly garbled output for words such as coward and we are skipping capitalized Cows. We can improve this with a pattern that anchors word boundaries and accepts a lower or upper case C:
Note that we defined a named pattern cow in The definitions section to match the start and end of a "cow" or capitalized "Cow" with the regex \<[Cc]ow\>. We use {cow} in our rule for matching. The matched text first character is emitted with text()[0] and we simply append a "hick" to complete our chick.
Note that regex grouping with parenthesis to capture text matched by a parenthesized sub-regex is generally not supported by scanner generators, so we have to use the entire matched text() string.
Flex and Lex do not support word boundary anchors \<, \>, \b, and \B, so this example only works with RE/flex.
If you are wondering about the action code in our example not exactly reflecting the C code expected with Flex, then rest assured that RE/flex supports the classic Flex and Lex actions such as yytext instead of text() and *yyout instead of out(). Simply use option −−flex to regress to the C-style Flex names and actions. Use options −−flex and −−bison (or option −−yy) to regress even further to generated a global yylex() function and "yy" variables.
To create a stand-alone scanner, we add main to the User code section:
The main function instantiates the lexer class and invokes the scanner, which will not return until the entire input is processed. In fact, you can let reflex generate this main function for you with option −−main.
More details on these three lexer specification sections is presented next.
The Definitions section includes name-pattern pairs to define names for patterns. Named patterns can be referenced in regex patterns by embracing them in { and }.
The following example defines two names for two patterns, where the second regex pattern uses the previously named pattern:
Patterns ending in an escape \ continue on the next line with optional line indentation. This permits you to organize your layout of long patterns. See also Free space mode to improve pattern readability.
Names must be defined before being referenced. Names are expanded as macros in regex patterns. For example, {digit}+ is expanded into [0-9]+.
φ then the expanded pattern φ is placed in a non-capturing group (?:φ) to preserve its structure. For example, {number} expands to (?:{digit}+) which in turn expands to (?:(?:[0-9])+).To inject code into the generated scanner, indent the code or place the code within a %{ %} block. The %{ and the matching %} should each be placed at the start of a new line. To inject code at the very top of the generated scanner, place this code within a %top{ } block:
The definitions section may also contain one or more options with %option (or %o for short). For example:
Multiple options can be grouped on the same line as is shown above. See Options for a list of available options.
freespace, case-insensitive, dotall, and unicode affect the named patterns defined in The definitions section. Therefore, we should place these options ahead of all named patterns. If a regex pattern specifically requires one or more of these options, use the (?isux:φ) modifier(s), see Patterns for details.Consider the following example. Say we want to count the number of occurrences of the word "cow" in some text. We declare a global counter, increment the counter when we see a "cow", and finally report the total tally when we reach the end of the input marked by the <<EOF>> rule:
The above works fine, but we are using a global counter which is not a best practice and is not thread-safe: multiple Lexer class instances may compete to bump the counter. Another problem is that the Lexer can only be used once, there is no proper initialization to restart the Lexer on new input.
RE/flex allows you to inject code in the generated Lexer class, meaning that class members and constructor code can be added to manage the Lexer class state. All Lexer class members are visible in actions, even when private. New Lexers can be instantiated given some input to scan. Lexers can run in parallel in threads without requiring synchronization when their state is part of the instance and not managed by global variables.
To inject Lexer class member declarations such as variables and methods, place the declarations within %class{ } block. The %class{ and the matching } should each be placed at the start of a new line.
Likewise, to inject Lexer class constructor code, for example to initialize members, place the code within %init{ } block. The %init{ and the matching } should each be placed at the start of a new line. Option %option ctorarg="argument, argument, ..." may be used to declare the constructor arguments of the Lexer class constructor. Option %option ctorinit="initializer, initializer, ..." specifies constructor initializers. See also The Lexer/yyFlexLexer class .
Additional constructors and/or a destructor may be placed in a %class{ } block, for class Lexer (or yyFlexLexer with option −−flex), unless the class is renamed with option −−lexer=NAME (%option lexer=NAME).
For convenience you can use the generated REFLEX_OPTION_lexer macro in your code that expands to the class name. To do so, use reflex option −−header-file to generate a header file to include in your code.
For example, we use these code injectors to make our cow counter herd part of the Lexer class state. We also add a sound "Moo!" when a cow was matched, to illustrate the use of a static data member that is initialized ouf of line:
Note that nothing else needs to be changed, because the actions are part of the generated Lexer class and can access the Lexer class members, which in this example is the member variable herd.
In this example, we just search for pattern matches and ignore everything else with a dot rule with no action. This dot matches newlines too because we specified option dotall. Searching for pattern matches like this example can be done much more efficiently with option find to generate a search engine instead of a scanner:
We should not forget to remove the dot rule from our lexer specification, otherwise we still match a lot that we don't need to match:
To modularize specifications of lexers, use %include (or %i for short) to include one or more files into The definitions section of a specification. For example:
This includes examples/jdefs.l with Java patterns into the current specification so you can match Java lexical structures, such as copying Java identifiers to the output given some Java source program as input:
Multiple files may be specified with one %include. Quotes may be omitted from the %include argument if the argument has no punctuation characters except . and -, for example %include jdefs.l.
To declare start condition state names use %state (or %s for short) to declare inclusive states and use %xstate (or %x for short) to declare exclusive states:
See Start condition states for more information about states.
Each rule in the rules section consists of a pattern-action pair separated by spacing after the pattern (unless free space mode is enabled). For example, the following defines an action for a pattern:
To add action code that spans multiple lines, indent the code or place the code in a { } block. When local variables are declared in an action then the code should always be placed in a block.
In free space mode you MUST place actions in { } blocks and user code in %{ %} blocks instead of indented, see Free space mode.
Actions in the rules section can use predefined RE/flex variables and functions. With reflex option −−flex, the variables and functions are the classic Flex actions shown in the second column of this table:
| RE/flex action | Flex action | Result |
|---|---|---|
text() | YYText(), yytext | 0-terminated text match |
str() | n/a | std::string text match |
strview() | n/a | std::string_view text match |
wstr() | n/a | std::wstring wide text match |
chr() | yytext[0] | first 8-bit char of text match |
wchr() | n/a | first wide char of text match |
chr_last() | yytext[yyleng-1] | last 8-bit char of text match |
wchr_last() | n/a | last wide char of text match |
chr_next() | n/a | next 8-bit char after text match |
wchr_next() | n/a | next wide char after text match |
size() | YYLeng(), yyleng | size of the match in bytes |
wsize() | n/a | number of wide chars matched |
lines() | n/a | number of lines matched (>=1) |
columns() | n/a | number of columns matched (>=0) |
lineno(n) | yylineno = n | set line number of the match to n |
lineno() | yylineno | line number of the match (>=1) |
columno(n) | n/a | set column number of the match to n |
columno() | n/a | column number of match (>=0) |
lineno_end() | n/a | ending line number of match (>=1) |
columno_end() | n/a | ending column number of match (>=0) |
border() | n/a | border of the match (>=0) |
echo() | ECHO | out().write(text(), size()) |
in(i) | yyrestart(i) | set input to reflex::Input i |
in(), in() = i | *yyin, yyin = &i | get/set reflex::Input i |
out(o) | yyout = &o | set output to std::ostream o |
out() | *yyout | get std::ostream object |
out().write(s, n) | LexerOutput(s, n) | output chars s[0..n-1] |
out().put(c) | output(c) | output char c |
start(n) | BEGIN n | set start condition to n |
start() | YY_START | get current start condition |
push_state(n) | yy_push_state(n) | push current state, start n |
pop_state() | yy_pop_state() | pop state and make it current |
top_state() | yy_top_state() | get top state start condition |
states_empty() | n/a | true if state stack is empty |
matcher().accept() | yy_act | number of the matched rule |
matcher().text() | YYText(), yytext | same as text() |
matcher().str() | n/a | same as str() |
matcher().wstr() | n/a | same as wstr() |
matcher().chr() | yytext[0] | same as chr() |
matcher().wchr() | n/a | same as wchr() |
matcher().chr_last() | yytext[yyleng-1] | same as chr_last() |
matcher().wchr_last() | n/a | same as wchr_last() |
matcher().chr_next() | n/a | same as chr_next() |
matcher().wchr_next() | n/a | same as wchr_next() |
matcher().size() | YYLeng(), yyleng | same as size() |
matcher().wsize() | n/a | same as wsize() |
matcher().lines() | n/a | same as lines() |
matcher().columns() | n/a | same as columns() |
matcher().lineno(n) | yylineno = n | same as lineno(n) |
matcher().lineno() | yylineno | same as lineno() |
matcher().columno(n) | */na* | same as columno(n) |
matcher().columno() | n/a | same as columno() |
matcher().lineno_end() | yylineno | same as lineno_end() |
matcher().columno_end() | n/a | same as columno_end() |
matcher().border() | n/a | same as border() |
matcher().begin() | n/a | non-0-terminated text match begin |
matcher().end() | n/a | non-0-terminated text match end |
matcher().input() | yyinput() | get next 8-bit char from input |
matcher().winput() | n/a | get wide character from input |
matcher().unput(c) | unput(c) | put back 8-bit char c |
matcher().wunput(c) | unput(c) | put back (wide) char c |
matcher().peek() | n/a | peek at next 8-bit char on input |
matcher().skip(c) | n/a | skip input to char c |
matcher().skip(s) | n/a | skip input to UTF-8 string s |
matcher().more() | yymore() | append next match to this match |
matcher().less(n) | yyless(n) | shrink match length to n |
matcher().first() | n/a | first pos of match in input |
matcher().last() | n/a | last pos+1 of match in input |
matcher().rest() | n/a | get rest of input until end |
matcher().span() | n/a | enlarge match to span line |
matcher().line() | n/a | get line with the match |
matcher().wline() | n/a | get line with the match |
matcher().at_bob() | n/a | true if at the begin of input |
matcher().at_end() | n/a | true if at the end of input |
matcher().at_bol() | YY_AT_BOL() | true if at begin of a newline |
set_debug(n) | set_debug(n) | reflex option -d sets n=1 |
debug() | debug() | nonzero when debugging |
A reflex::Input input source is denoted i in the table, which can be FILE* descriptor, std::istream, a string std::string or const char*, or a wide string std::wstring or const wchar_t*. Output o is a std::ostream object.
Note that Flex switch_streams(i, o) is the same as invoking the in(i) and out(o) methods. Flex yyrestart(i) is the same as invoking in(i) to set input to a file, stream, or string. Invoking switch_streams(i, o) and in(i) also resets the lexer's matcher (internally with matcher.reset()). This clears the line and column counters, resets the internal anchor and boundary flags for anchor and word boundary matching, and resets the matcher to consume buffered input.
You can also set the input with in() = i (or yyin = &i) with option −−flex). This however does not reset the matcher. This means that when an end of input (EOF) was reached, you should clear the EOF state first with matcher().set_end(false) or reset the matcher state with matcher().reset(). Resetting the matcher state also flushes the remaining input from the buffer, which would otherwise still be consumed. Using in(i) (or yyrestart(i) with option −−flex) is therefore preferable.
The matcher().input(), matcher().winput(), and matcher().peek() methods return a non-negative character code and EOF (-1) when the end of input is reached. These methods preserve the current text() match (and yytext with option −−flex), but the pointer returned by text() (and yytext) may change after these methods are called. However, the yytext pointer is not preserved when using these methods with reflex options −−flex and −−bison.
yyinput() function returns 0 when the end of input is reached, which makes it impossible to distinguish \0 (NUL) from EOF. By contrast, matcher().input() returns EOF (-1) when the end of the input is reached.matcher() before the lex() (or yylex() with option −−flex) is invoked! A matcher is not initially assigned to a lexer when the lexer is constructed, leaving matcher() undefined.The matcher().skip(c) method skips input until char or wide wchar_t character c is consumed and returns true when found. This method changes text() (and yytext with option −−flex). This method is more efficient than repeatedly calling matcher().input(). Likewise, matcher().skip(s) skips input until UTF-8 string s is consumed and returns true when found.
Use reflex options −−flex and −−bison (or option −−yy) to enable global Flex actions and variables. This makes Flex actions and variables globally accessible outside of The rules section, with the exception of yy_push_state(), yy_pop_state(), yy_top_state(). Outside The rules section you must use the global action yyinput() instead of input(), global action yyunput() instead of unput(), and global action yyoutput() instead of output(). Because yyin and yyout are macros they cannot be (re)declared or accessed as global variables, but they can be used as if these were variables. To avoid compilation errors, use reflex option −−header-file to generate a header file lex.yy.h to include in your code to use the global use Flex actions and variables. See Interfacing with Bison/Yacc for more details on the −−bison options to use.
When using reflex options −−flex, −−bison and −−reentrant, most Flex functions take a yyscan_t scanner as an extra last argument. See Reentrant scanners for details.
From the first couple of entries in the table shown above you may have guessed correctly that text() is just a shorthand for matcher().text(), since matcher() is the matcher object associated with the generated Lexer class. The same shorthand apply to str(), wstr(), size(), wsize(), lineno(), columno(), and border(). Use text() for fast access to the matched text. The str() method returns a string copy of the match and is less efficient. Likewise, wstr() returns a wide string copy of the match, converted from UTF-8.
The lineno() method returns the line number of the match, starting at line 1. The ending line number is lineno_end(), which is identical to the value of lineno() + lines() - 1.
The columno() method returns the column offset of a match from the start of the line, beginning at column 0. This method takes tab spacing and wide characters into account. The inclusive ending column number is given by columno_end(), which is equal or larger than columno() if the match does not span multiple lines. Otherwise, if the match spans multiple lines, columno_end() is the ending column of the match on the last matching line.
The lines() and columns() methods return the number of lines and columns matched, where columns() takes tab spacing and wide characters into account. If the match spans multiple lines, columns() counts columns over all lines, without counting the newline characters.
The starting byte offset of the match on a line is border() and the inclusive ending byte offset of the match is border() + size() - 1.
columno(), columno_end(), and columns() do not take the character display width of full-width and combining Unicode characters into account. It is recommended to use the wcwidth function or wcwidth.c to determine Unicode character widths.The matcher().more() method is used to create longer matches by stringing together consecutive matches in the input after scanning the input with the scan() method. When this method is invoked, the next match with scan() has its matched text prepended to it. The matcher().more() operation is often used in lexers and was introduced in Lex.
The matcher().less(n) method reduces the size of the matched text to n bytes. This method has no effect if n is larger than size(). The value of n should not be 0 to prevent infinite looping on the same input as no input is consumed (or you could switch to another start condition state with start(n) in the action that uses less(0)). The matcher().less(n) operation was introduced in Lex and is often used in lexers to place input back into the input stream and as a means to perform sophisticated lookaheads.
The matcher().first() and matcher().last() methods return the position in the input stream of the match, counting in bytes from the start of the input at position 0. If the input stream is a wide character sequence, the UTF-8 positions are returned as a result of the internally-converted UTF-8 wide character input.
The matcher().rest() method returns the rest of the input character sequence as a 0-terminated char* string. This method buffers all remaining input to return the string.
The matcher().span() method enlarges the text matched to span the entire line and returns the matching line as a 0-terminated char* string without the \n.
The matcher().line() and matcher().wline() methods return the entire line as a (wide) string with the matched text as a substring. These methods can be used to obtain the context of a match, for example to display the line where a lexical error or syntax error occurred.
matcher().span(), matcher().line(), and matcher().wline() invalidate the previous text(), yytext, strview(), begin(), bol(), and end() string pointers. Call these methods again to retrieve the updated pointer or call str() or wstr() to obtain a string copy of the match: reflex::AbstractMatcher::Const::BUFSZ. When this length is exceeded, the line's length before the match is truncated. This ensures that pattern matching binary files or files with very long lines cannot cause memory allocation exceptions.Because matcher() returns the current matcher object, the following Flex-like actions are also supported:
| RE/flex action | Flex action | Result |
|---|---|---|
matcher().buffer() | n/a | buffer entire input |
matcher().buffer(n) | n/a | set buffer size to n |
matcher().interactive() | yy_set_interactive(1) | set interactive input |
matcher().flush() | YY_FLUSH_BUFFER | flush input buffer |
matcher().set_bol(b) | yy_set_bol(b) | (re)set begin of line |
matcher().set_bob(b) | n/a | (re)set begin of input |
matcher().set_end(b) | n/a | (re)set end of input |
matcher().reset() | n/a | reset the state as new |
You can switch to a new matcher while scanning input, and use operations to create a new matcher, push/pop a matcher on/from a stack, and delete a matcher:
| RE/flex action | Flex action | Result |
|---|---|---|
matcher(m) | yy_switch_to_buffer(m) | use matcher m |
new_matcher(i) | yy_create_buffer(i, n) | returns new matcher for reflex::Input i |
del_matcher(m) | yy_delete_buffer(m) | delete matcher m |
push_matcher(m) | yypush_buffer_state(m) | push current matcher, then use m |
pop_matcher() | yypop_buffer_state() | pop matcher and delete current |
ptr_matcher() | YY_CURRENT_BUFFER | pointer to current matcher |
has_matcher() | YY_CURRENT_BUFFER != 0 | current matcher is usable |
The matcher type m is a Lexer class-specific Matcher type, which depends on the underlying matcher used by the scanner. Therefore, new_matcher(i) instantiates a reflex::Matcher or the matcher specified with the −−matcher option.
The push_matcher() and pop_matcher() functions can be used to temporarily switch to another input source while preserving the original input source associated with the matcher on the stack with push_matcher(). The pop_matcher() action returns true when successful and false otherwise, when the stack is empty. When false, has_matcher() returns false and ptr_matcher() returns NULL. See also Multiple input sources .
The following Flex actions are also supported with reflex option −−flex:
| RE/flex action | Flex action | Result |
|---|---|---|
in(s) | yy_scan_string(s) | reset and scan string s (std::string or char*) |
in(s) | yy_scan_wstring(s) | reset and scan wide string s (std::wstring or wchar_t*) |
in(b, n) | yy_scan_bytes(b, n) | reset and scan n bytes at address b (buffered) |
buffer(b, n+1) | yy_scan_buffer(b, n+2) | reset and scan n bytes at address b (zero copy) |
These functions create a new buffer (i.e. a new matcher in RE/flex) to incrementally buffer the input on demand, except for yy_scan_buffer that scans a string in place (i.e. zero copy) that should end with two zero bytes, which are included in the specified length. A pointer to the new buffer is returned, which becomes the YY_CURRENT_BUFFER. You should delete the old buffer with yy_delete_buffer(YY_CURRENT_BUFFER) before creating a new buffer with one of these functions. See Switching input sources for more details.
The generated scanner reads from the standard input by default or from an input source specified as a reflex::Input object, such as a string, wide string, file, or a stream. See Switching input sources for more details on managing the input to a scanner.
These functions take an extra last yyscan_t argument for reentrant scanners generated with option −−reentrant. This argument is a pointer to a lexer object. See Reentrant scanners for more details.
To inject code at the end of the generated scanner, such as a main function, we can use the third and final User code section. All of the code in the User code section is copied to the generated scanner.
Below is a User code section example with main that invokes the lexer to read from standard input (the default input) and display all numbers found:
You can also automatically generate a main with the reflex −−main option, which will produce the same main function shown in the example above. This creates a stand-alone scanner that instantiates a Lexer that reads input from standard input.
To scan from other input than standard input, such as from files, streams, and strings, instantiate the Lexer class with the input source as the first argument. To set an alternative output stream than standard output, pass a std::ostream object as the second argument to the Lexer class constructor:
The above uses a FILE descriptor to read input from, which has the advantage of automatically decoding UTF-8/16/32 input. Other permissible input sources are std::istream, std::string, std::wstring, char*, and wchar_t*.
The regex pattern syntax you can use generally depends on the regex matcher library that you use. Fortunately, RE/flex accept a broad pattern syntax for lexer specifications. The reflex command internally converts the regex patterns to regex forms that the underlying matcher engine library can handle (except when specifically indicated in the tables that follow). This ensures that the same pattern syntax can be used with any matcher engine library that RE/flex currently supports.
A pattern is an extended set of regular expressions, with nested sub-expression patterns φ and ψ:
| Pattern | Matches |
|---|---|
x | matches the character x, where x is not a special character |
. | matches any single character or a byte, except newline (unless in dotall mode) |
\. | matches . (dot), special characters are escaped with a backslash |
\n | matches a newline, others are \a (BEL), \b (BS), \t (HT), \v (VT), \f (FF), and \r (CR) |
\N | matches any single character except newline |
\0 | matches the NUL character |
\cX | matches the control character X mod 32 (e.g. \cA is \x01) |
\0141 | matches an 8-bit character with octal value 141 (use \141 in lexer specifications instead, see below) |
\x7f | matches an 8-bit character with hexadecimal value 7f |
\x{3B1} | matches Unicode character U+03B1, i.e. α |
\u{3B1} | matches Unicode character U+03B1, i.e. α |
\o{141} | matches U+0061, i.e. a, in octal |
\p{C} | matches a character in category C of Character categories |
\Q...\E | matches the quoted content between \Q and \E literally |
[abc] | matches one of a, b, or c as Character classes |
[0-9] | matches a digit 0 to 9 as Character classes |
[^0-9] | matches any character except a digit as Character classes |
φ? | matches φ zero or one time (optional) |
φ* | matches φ zero or more times (repetition) |
φ+ | matches φ one or more times (repetition) |
φ{2,5} | matches φ two to five times (repetition) |
φ{2,} | matches φ at least two times (repetition) |
φ{2} | matches φ exactly two times (repetition) |
φ?? | matches φ zero or once as needed (lazy optional) |
φ*? | matches φ a minimum number of times as needed (lazy repetition) |
φ+? | matches φ a minimum number of times at least once as needed (lazy repetition) |
φ{2,5}? | matches φ two to five times as needed (lazy repetition) |
φ{2,}? | matches φ at least two times or more as needed (lazy repetition) |
φψ | matches φ then matches ψ (concatenation) |
φ⎮ψ | matches φ or matches ψ (alternation) |
(φ) | matches φ as a group to capture (this is non-capturing in lexer specifications) |
(?:φ) | matches φ without group capture |
(?=φ) | matches φ without consuming it (Lookahead) |
(?<=φ) | matches φ to the left without consuming it (Lookbehind, not supported by the RE/flex matcher) |
(?^φ) | matches φ and ignores it, marking everything as a non-match to continue matching (RE/flex matcher only) |
^φ | matches φ at the begin of input or begin of a line (requires multi-line mode) (top-level φ only, not nested in a sub-pattern) |
φ$ | matches φ at the end of input or end of a line (requires multi-line mode) (top-level φ only, not nested in a sub-pattern) |
\Aφ | matches φ at the begin of input (top-level φ, not nested in a sub-pattern) |
φ\z | matches φ at the end of input (top-level φ, not nested in a sub-pattern) |
\bφ | matches φ starting at a word boundary |
φ\b | matches φ ending at a word boundary |
\Bφ | matches φ starting at a non-word boundary |
φ\B | matches φ ending at a non-word boundary |
\<φ | matches φ that starts a word |
\>φ | matches φ that starts a non-word |
φ\< | matches φ that ends a non-word |
φ\> | matches φ that ends a word |
\i | matches an indent for Indent/nodent/dedent matching |
\j | matches a dedent for Indent/nodent/dedent matching |
\k | matches if indent depth changed, undoing this change to keep the current indent stops for Indent/nodent/dedent matching |
(?i:φ) | Case-insensitive mode matches φ ignoring case |
(?m:φ) | Multi-line mode ^ and $ in φ match begin and end of a line (default in lexer specifications) |
(?s:φ) | Dotall mode . (dot) in φ matches newline |
(?u:φ) | Unicode mode ., \s, \w, \l, \u, \S, \W, \L, \U match Unicode |
(?x:φ) | Free space mode ignore all whitespace and comments in φ |
(?#:X) | all of X is skipped as a comment |
Word boundaries \<, \>, \b and \B demarcate words. Word characters are letters, digits, and the underscore. Anchors \A and \z demarcate the begin and end of the input, respectively. Anchors ^ and $ demarcate the begin and end of a line, respectively, because multi-line mode is enabled by default in all RE/flex-generated scanners. See also Anchors and boundaries.
Indentation matching with \i, \j and \k is a RE/flex feature available only with the RE/flex regex library that supports it. See also Indent/nodent/dedent for more details.
? for optional patterns φ?? and repetitions φ*? φ+? is not supported by Boost.Regex in POSIX mode. In general, POSIX matchers do not support lazy quantifiers due to POSIX limitations that are rooted in the theory of formal languages FSM of regular expressions. The RE/flex regex library is regex POSIX compliant and supports lazy quantifiers as an addition.−−fast does not produce code that backtracks, which means that patterns such as bar.*\bfoo that require backtracking on \b may not work properly. If necessary, use option −−full when word boundaries are used when these require backtracking to find a match.The following patterns are available in RE/flex and adopt the same Flex/Lex patterns syntax. These pattern should only be used in lexer specifications:
| Pattern | Matches |
|---|---|
\177 | matches an 8-bit character with octal value 177 |
"..." | matches the quoted content literally |
φ/ψ | matches φ if followed by ψ as a Trailing context |
<S>φ | matches φ only if state S is enabled in Start condition states |
<S1,S2,S3>φ | matches φ only if state S1, S2, or state S3 is enabled in Start condition states |
<*>φ | matches φ in any state of the Start condition states |
<<EOF>> | matches EOF in any state of the Start condition states |
<S><<EOF>> | matches EOF only if state S is enabled in Start condition states |
[a-z││[A-Z]] | matches a letter, see Character classes |
[a-z&&[^aeiou]] | matches a consonant, see Character classes |
[a-z−−[aeiou]] | matches a consonant, see Character classes |
[a-z]{+}[A-Z] | matches a letter, same as [a-z││[A-Z]], see Character classes |
[a-z]{│}[A-Z] | matches a letter, same as [a-z││[A-Z]], see Character classes |
[a-z]{&}[^aeiou] | matches a consonant, same as [a-z&&[^aeiou]], see Character classes |
[a-z]{-}[aeiou] | matches a consonant, same as [a-z−−[aeiou]], see Character classes |
Note that the characters . (dot), \, ?, *, +, |, (, ), [, ], {, }, ^, and $ are meta-characters and should be escaped to match. Lexer specifications also include the " and / as meta-characters and these should be escaped to match.
Spaces and tabs cannot be matched in patterns in lexer specifications. To match the space character use " " or [ ] and to match the tab character use \t. Use \h to match a space or tab.
The order of precedence for composing larger patterns from sub-patterns is as follows, from high to low precedence:
(φ), (?:φ), (?=φ), and inline modifiers (?imsux-imsux:φ)?, *, +, {n,m}φψ (including trailing context φ/ψ)^, $, \<, \>, \b, \B, \A, \zφ|ψ(?imsux-imsux)φ?? in regex strings. Instead, use at least one escaped question mark, such as ?\?, which the compiler will translate to ??. This problem does not apply to lexer specifications that the reflex command converts to regex strings. Fortunately, most C++ compilers ignore trigraphs unless in standard-conforming modes, such as -ansi and -std=c++98.Character classes in bracket lists represent sets of characters. Sets can be negated (or inverted), subtracted, intersected, and merged (except for the PCRE2Matcher):
| Pattern | Matches |
|---|---|
[a-zA-Z] | matches a letter |
[^a-zA-Z] | matches a non-letter (character class negation) |
[a-z││[A-Z]] | matches a letter (character class union) |
[a-z&&[^aeiou]] | matches a consonant (character class intersection) |
[a-z−−[aeiou]] | matches a consonant (character class subtraction) |
Bracket lists cannot be empty, so [] and [^] are invalid. In fact, the first character after the bracket is always part of the list. So [][] is a list that matches a ] and a [, [^][] is a list that matches anything but ] and [, and [-^] is a list that matches a - and a ^.
It is an error to construct an empty character class by subtraction or by intersection, for example [a&&[b]] is invalid.
Bracket lists may contain ASCII and Unicode Character categories, for example [a-z\d] contains the letters a to z and digits 0 to 9 (or Unicode digits when Unicode is enabled). To add Unicode character categories and wide characters (encoded in UTF-8) to bracket lists Unicode mode should be enabled.
An negated Unicode character class is constructed by subtracting the character class from the Unicode range U+0000 to U+D7FF and U+E000 to U+10FFFF.
Character class operations can be chained together in a bracket list. The union ||, intersection &&, and subtraction -- operations are left associative and have the same operator precedence. For example, [a-z||[A-Z]--[aeiou]--[AEIOU]], [a-z--[aeiou]||[A-Z]--[AEIUO]], [a-z&&[^aeiou]||[A-Z]&&[^AEIOU]], and [B-DF-HJ-NP-TV-Zb-df-hj-np-tv-z] are the same character classes.
Character class operations may be nested. For example, [a-z||[A-Z||[0-9]]] is the same as [a-zA-Z0-9].
Character class negation, when specified, is applied to the resulting character class after the character class operations are applied. For example, [^a-z||[A-Z]] is the same as [^||[a-z]||[A-Z]], which is the class [^a-zA-Z].
Note that negated character classes such as [^a-zA-Z] match newlines when \n is not included in the class. Include \n in the negated character class to prevent matching newlines. The reflex::convert_flag::notnewline removes newlines from character classes when used with Regex converters , except for patterns \P{C}, \R, \D, \H, and \W.
A lexer specification may use a defined name in place of the second operand of a character class operation. A defined name when used as an operand should expand into a POSIX character class containing ASCII characters only. For example:
||, &&, and a -- operator in a bracket list. Do not place a defined name as the first operand to a union, intersection, and subtraction operation, because the definition is not expanded. For example, [{lower}||{upper}] contains [A-Zelorw{}]. The name and the {, } characters are literally included in the resulting character class. Instead, this bracket list should be written as [||{lower}||{upper}]. Likewise, [^{lower}||{upper}] should be written as [^||{lower}||{upper}].Alternatively, unions may be written as alternations. That is, [||{name1}||{name2}||{name3}||...] can be written as ({name1}|{name2}|{name3}|...), where the latter form supports full Unicode not restricted to ASCII.
The character class operators {+} (or {|}), {&}, and {-} may be used in lexer specifications. Note that Flex only supports the two operators {+} and {-}:
| Pattern | Matches |
|---|---|
[a-z]{+}[A-Z] | matches a letter, same as [a-z││[A-Z]] |
[a-z]{│}[A-Z] | matches a letter, same as [a-z││[A-Z]] |
[a-z]{&}[^aeiou] | matches a consonant, same as [a-z&&[^aeiou]] |
[a-z]{-}[aeiou] | matches a consonant, same as [a-z−−[aeiou]] |
Multiple operators can be chained together. Unlike Flex, defined names may be used as operands. For example {lower}{+}{upper} is the same as [a-z]{+}[A-Z], i.e. the character class [A-Za-z]. A defined name when used as an operand should expand into a POSIX character class containing ASCII characters only.
The 7-bit ASCII POSIX character categories are:
| POSIX form | Matches |
|---|---|
[:ascii:] | matches any ASCII character |
[:space:] | matches a white space character [ \t\n\v\f\r] |
[:xdigit:] | matches a hex digit [0-9A-Fa-f] |
[:cntrl:] | matches a control character [\x00-\x1f\x7f] |
[:print:] | matches a printable character [\x20-\x7e] |
[:alnum:] | matches a alphanumeric character [0-9A-Za-z] |
[:alpha:] | matches a letter [A-Za-z] |
[:blank:] | matches a blank character \h same as [ \t] |
[:digit:] | matches a digit [0-9] |
[:graph:] | matches a visible character [\x21-\x7e] |
[:lower:] | matches a lower case letter [a-z] |
[:punct:] | matches a punctuation character [\x21-\x2f\x3a-\x40\x5b-\x60\x7b-\x7e] |
[:upper:] | matches an upper case letter [A-Z] |
[:word:] | matches a word character [0-9A-Za-z_] |
[:^blank:] | matches a non-blank character \H same as [^ \t] |
[:^digit:] | matches a non-digit [^0-9] |
The POSIX forms are used in bracket lists. For example [[:lower:][:digit:]] matches an ASCII lower case letter or a digit.
You can also use the upper case \P{C} form that has the same meaning as \p{^C}, which matches any character except characters in the class C. For example, \P{ASCII} is the same as \p{^ASCII} which is the same as [^[:ascii:]].
When Unicode matching mode is enabled, [^[:ascii]] is a Unicode character class that excludes the ASCII character category. Unicode character classes and categories require the reflex −−unicode option.
The following Unicode character categories are enabled with the reflex −−unicode option or Unicode mode (?u:φ) and with the regex matcher converter flag reflex::convert_flag::unicode when using a regex library:
| Unicode category | Matches |
|---|---|
. | matches any single character (or a byte in Unicode mode, see Invalid UTF encodings and the dot pattern ) |
\a | matches BEL U+0007 |
\d | matches a digit \p{Nd} |
\D | matches a non-digit |
\e | matches ESC U+001b |
\f | matches FF U+000c |
\h | matches a blank [ \t] |
\H | matches a non-blank [^ \t] |
\l | matches a lower case letter \p{Ll} |
\n | matches LF U+000a |
\N | matches any non-LF character |
\r | matches CR U+000d |
\R | matches a Unicode line break |
\s | matches a white space character [ \t\n\v\f\r\x85\p{Z}] |
\S | matches a non-white space character |
\t | matches TAB U+0009 |
\u | matches an upper case letter \p{Lu} |
\v | matches VT U+000b |
\w | matches a Unicode word character [\p{L}\p{Nd}\p{Pc}] |
\W | matches a non-Unicode word character |
\X | matches any ISO-8859-1 or Unicode character |
\p{Space} | matches a white space character [ \t\n\v\f\r\x85\p{Z}] |
\p{Unicode} | matches any Unicode character U+0000 to U+10FFFF minus U+D800 to U+DFFF |
\p{ASCII} | matches an ASCII character U+0000 to U+007F |
\p{Non_ASCII_Unicode} | matches a non-ASCII character U+0080 to U+10FFFF minus U+D800 to U+DFFF) |
\p{L&} | matches a character with Unicode property L& (i.e. property Ll, Lu, or Lt) |
\p{Letter},\p{L} | matches a character with Unicode property Letter |
\p{Mark},\p{M} | matches a character with Unicode property Mark |
\p{Separator},\p{Z} | matches a character with Unicode property Separator |
\p{Symbol},\p{S} | matches a character with Unicode property Symbol |
\p{Number},\p{N} | matches a character with Unicode property Number |
\p{Punctuation},\p{P} | matches a character with Unicode property Punctuation |
\p{Other},\p{C} | matches a character with Unicode property Other |
\p{Lowercase_Letter}, \p{Ll} | matches a character with Unicode sub-property Ll |
\p{Uppercase_Letter}, \p{Lu} | matches a character with Unicode sub-property Lu |
\p{Titlecase_Letter}, \p{Lt} | matches a character with Unicode sub-property Lt |
\p{Modifier_Letter}, \p{Lm} | matches a character with Unicode sub-property Lm |
\p{Other_Letter}, \p{Lo} | matches a character with Unicode sub-property Lo |
\p{Non_Spacing_Mark}, \p{Mn} | matches a character with Unicode sub-property Mn |
\p{Spacing_Combining_Mark}, \p{Mc} | matches a character with Unicode sub-property Mc |
\p{Enclosing_Mark}, \p{Me} | matches a character with Unicode sub-property Me |
\p{Space_Separator}, \p{Zs} | matches a character with Unicode sub-property Zs |
\p{Line_Separator}, \p{Zl} | matches a character with Unicode sub-property Zl |
\p{Paragraph_Separator}, \p{Zp} | matches a character with Unicode sub-property Zp |
\p{Math_Symbol}, \p{Sm} | matches a character with Unicode sub-property Sm |
\p{Currency_Symbol}, \p{Sc} | matches a character with Unicode sub-property Sc |
\p{Modifier_Symbol}, \p{Sk} | matches a character with Unicode sub-property Sk |
\p{Other_Symbol}, \p{So} | matches a character with Unicode sub-property So |
\p{Decimal_Digit_Number}, \p{Nd} | matches a character with Unicode sub-property Nd |
\p{Letter_Number}, \p{Nl} | matches a character with Unicode sub-property Nl |
\p{Other_Number}, \p{No} | matches a character with Unicode sub-property No |
\p{Dash_Punctuation}, \p{Pd} | matches a character with Unicode sub-property Pd |
\p{Open_Punctuation}, \p{Ps} | matches a character with Unicode sub-property Ps |
\p{Close_Punctuation}, \p{Pe} | matches a character with Unicode sub-property Pe |
\p{Initial_Punctuation}, \p{Pi} | matches a character with Unicode sub-property Pi |
\p{Final_Punctuation}, \p{Pf} | matches a character with Unicode sub-property Pf |
\p{Connector_Punctuation}, \p{Pc} | matches a character with Unicode sub-property Pc |
\p{Other_Punctuation}, \p{Po} | matches a character with Unicode sub-property Po |
\p{Control}, \p{Cc} | matches a character with Unicode sub-property Cc |
\p{Format}, \p{Cf} | matches a character with Unicode sub-property Cf |
\p{UnicodeIdentifierStart} | matches a character in the Unicode IdentifierStart class |
\p{UnicodeIdentifierPart} | matches a character in the Unicode IdentifierPart class |
\p{IdentifierIgnorable} | matches a character in the IdentifierIgnorable class |
\p{JavaIdentifierStart} | matches a character in the Java IdentifierStart class |
\p{JavaIdentifierPart} | matches a character in the Java IdentifierPart class |
\p{CsIdentifierStart} | matches a character in the C# IdentifierStart class |
\p{CsIdentifierPart} | matches a character in the C# IdentifierPart class |
\p{PythonIdentifierStart} | matches a character in the Python IdentifierStart class |
\p{PythonIdentifierPart} | matches a character in the Python IdentifierPart class |
To specify a Unicode block as a category when using the −−unicode option, use \p{IsBlockName}. The table below lists the block categories:
| IsBlockName | Unicode character range |
|---|---|
\p{IsBasicLatin} | U+0000 to U+007F |
\p{IsLatin-1Supplement} | U+0080 to U+00FF |
\p{IsLatinExtended-A} | U+0100 to U+017F |
\p{IsLatinExtended-B} | U+0180 to U+024F |
\p{IsIPAExtensions} | U+0250 to U+02AF |
\p{IsSpacingModifierLetters} | U+02B0 to U+02FF |
\p{IsCombiningDiacriticalMarks} | U+0300 to U+036F |
\p{IsGreekandCoptic} | U+0370 to U+03FF |
\p{IsCyrillic} | U+0400 to U+04FF |
\p{IsCyrillicSupplement} | U+0500 to U+052F |
\p{IsArmenian} | U+0530 to U+058F |
\p{IsHebrew} | U+0590 to U+05FF |
\p{IsArabic} | U+0600 to U+06FF |
\p{IsSyriac} | U+0700 to U+074F |
\p{IsArabicSupplement} | U+0750 to U+077F |
\p{IsThaana} | U+0780 to U+07BF |
\p{IsNKo} | U+07C0 to U+07FF |
\p{IsSamaritan} | U+0800 to U+083F |
\p{IsMandaic} | U+0840 to U+085F |
\p{IsSyriacSupplement} | U+0860 to U+086F |
\p{IsArabicExtended-B} | U+0870 to U+089F |
\p{IsArabicExtended-A} | U+08A0 to U+08FF |
\p{IsDevanagari} | U+0900 to U+097F |
\p{IsBengali} | U+0980 to U+09FF |
\p{IsGurmukhi} | U+0A00 to U+0A7F |
\p{IsGujarati} | U+0A80 to U+0AFF |
\p{IsOriya} | U+0B00 to U+0B7F |
\p{IsTamil} | U+0B80 to U+0BFF |
\p{IsTelugu} | U+0C00 to U+0C7F |
\p{IsKannada} | U+0C80 to U+0CFF |
\p{IsMalayalam} | U+0D00 to U+0D7F |
\p{IsSinhala} | U+0D80 to U+0DFF |
\p{IsThai} | U+0E00 to U+0E7F |
\p{IsLao} | U+0E80 to U+0EFF |
\p{IsTibetan} | U+0F00 to U+0FFF |
\p{IsMyanmar} | U+1000 to U+109F |
\p{IsGeorgian} | U+10A0 to U+10FF |
\p{IsHangulJamo} | U+1100 to U+11FF |
\p{IsEthiopic} | U+1200 to U+137F |
\p{IsEthiopicSupplement} | U+1380 to U+139F |
\p{IsCherokee} | U+13A0 to U+13FF |
\p{IsUnifiedCanadianAboriginalSyllabics} | U+1400 to U+167F |
\p{IsOgham} | U+1680 to U+169F |
\p{IsRunic} | U+16A0 to U+16FF |
\p{IsTagalog} | U+1700 to U+171F |
\p{IsHanunoo} | U+1720 to U+173F |
\p{IsBuhid} | U+1740 to U+175F |
\p{IsTagbanwa} | U+1760 to U+177F |
\p{IsKhmer} | U+1780 to U+17FF |
\p{IsMongolian} | U+1800 to U+18AF |
\p{IsUnifiedCanadianAboriginalSyllabicsExtended} | U+18B0 to U+18FF |
\p{IsLimbu} | U+1900 to U+194F |
\p{IsTaiLe} | U+1950 to U+197F |
\p{IsNewTaiLue} | U+1980 to U+19DF |
\p{IsKhmerSymbols} | U+19E0 to U+19FF |
\p{IsBuginese} | U+1A00 to U+1A1F |
\p{IsTaiTham} | U+1A20 to U+1AAF |
\p{IsCombiningDiacriticalMarksExtended} | U+1AB0 to U+1AFF |
\p{IsBalinese} | U+1B00 to U+1B7F |
\p{IsSundanese} | U+1B80 to U+1BBF |
\p{IsBatak} | U+1BC0 to U+1BFF |
\p{IsLepcha} | U+1C00 to U+1C4F |
\p{IsOlChiki} | U+1C50 to U+1C7F |
\p{IsCyrillicExtended-C} | U+1C80 to U+1C8F |
\p{IsGeorgianExtended} | U+1C90 to U+1CBF |
\p{IsSundaneseSupplement} | U+1CC0 to U+1CCF |
\p{IsVedicExtensions} | U+1CD0 to U+1CFF |
\p{IsPhoneticExtensions} | U+1D00 to U+1D7F |
\p{IsPhoneticExtensionsSupplement} | U+1D80 to U+1DBF |
\p{IsCombiningDiacriticalMarksSupplement} | U+1DC0 to U+1DFF |
\p{IsLatinExtendedAdditional} | U+1E00 to U+1EFF |
\p{IsGreekExtended} | U+1F00 to U+1FFF |
\p{IsGeneralPunctuation} | U+2000 to U+206F |
\p{IsSuperscriptsandSubscripts} | U+2070 to U+209F |
\p{IsCurrencySymbols} | U+20A0 to U+20CF |
\p{IsCombiningDiacriticalMarksforSymbols} | U+20D0 to U+20FF |
\p{IsLetterlikeSymbols} | U+2100 to U+214F |
\p{IsNumberForms} | U+2150 to U+218F |
\p{IsArrows} | U+2190 to U+21FF |
\p{IsMathematicalOperators} | U+2200 to U+22FF |
\p{IsMiscellaneousTechnical} | U+2300 to U+23FF |
\p{IsControlPictures} | U+2400 to U+243F |
\p{IsOpticalCharacterRecognition} | U+2440 to U+245F |
\p{IsEnclosedAlphanumerics} | U+2460 to U+24FF |
\p{IsBoxDrawing} | U+2500 to U+257F |
\p{IsBlockElements} | U+2580 to U+259F |
\p{IsGeometricShapes} | U+25A0 to U+25FF |
\p{IsMiscellaneousSymbols} | U+2600 to U+26FF |
\p{IsDingbats} | U+2700 to U+27BF |
\p{IsMiscellaneousMathematicalSymbols-A} | U+27C0 to U+27EF |
\p{IsSupplementalArrows-A} | U+27F0 to U+27FF |
\p{IsBraillePatterns} | U+2800 to U+28FF |
\p{IsSupplementalArrows-B} | U+2900 to U+297F |
\p{IsMiscellaneousMathematicalSymbols-B} | U+2980 to U+29FF |
\p{IsSupplementalMathematicalOperators} | U+2A00 to U+2AFF |
\p{IsMiscellaneousSymbolsandArrows} | U+2B00 to U+2BFF |
\p{IsGlagolitic} | U+2C00 to U+2C5F |
\p{IsLatinExtended-C} | U+2C60 to U+2C7F |
\p{IsCoptic} | U+2C80 to U+2CFF |
\p{IsGeorgianSupplement} | U+2D00 to U+2D2F |
\p{IsTifinagh} | U+2D30 to U+2D7F |
\p{IsEthiopicExtended} | U+2D80 to U+2DDF |
\p{IsCyrillicExtended-A} | U+2DE0 to U+2DFF |
\p{IsSupplementalPunctuation} | U+2E00 to U+2E7F |
\p{IsCJKRadicalsSupplement} | U+2E80 to U+2EFF |
\p{IsKangxiRadicals} | U+2F00 to U+2FDF |
\p{IsIdeographicDescriptionCharacters} | U+2FF0 to U+2FFF |
\p{IsCJKSymbolsandPunctuation} | U+3000 to U+303F |
\p{IsHiragana} | U+3040 to U+309F |
\p{IsKatakana} | U+30A0 to U+30FF |
\p{IsBopomofo} | U+3100 to U+312F |
\p{IsHangulCompatibilityJamo} | U+3130 to U+318F |
\p{IsKanbun} | U+3190 to U+319F |
\p{IsBopomofoExtended} | U+31A0 to U+31BF |
\p{IsCJKStrokes} | U+31C0 to U+31EF |
\p{IsKatakanaPhoneticExtensions} | U+31F0 to U+31FF |
\p{IsEnclosedCJKLettersandMonths} | U+3200 to U+32FF |
\p{IsCJKCompatibility} | U+3300 to U+33FF |
\p{IsCJKUnifiedIdeographsExtensionA} | U+3400 to U+4DBF |
\p{IsYijingHexagramSymbols} | U+4DC0 to U+4DFF |
\p{IsCJKUnifiedIdeographs} | U+4E00 to U+9FFF |
\p{IsYiSyllables} | U+A000 to U+A48F |
\p{IsYiRadicals} | U+A490 to U+A4CF |
\p{IsLisu} | U+A4D0 to U+A4FF |
\p{IsVai} | U+A500 to U+A63F |
\p{IsCyrillicExtended-B} | U+A640 to U+A69F |
\p{IsBamum} | U+A6A0 to U+A6FF |
\p{IsModifierToneLetters} | U+A700 to U+A71F |
\p{IsLatinExtended-D} | U+A720 to U+A7FF |
\p{IsSylotiNagri} | U+A800 to U+A82F |
\p{IsCommonIndicNumberForms} | U+A830 to U+A83F |
\p{IsPhags-pa} | U+A840 to U+A87F |
\p{IsSaurashtra} | U+A880 to U+A8DF |
\p{IsDevanagariExtended} | U+A8E0 to U+A8FF |
\p{IsKayahLi} | U+A900 to U+A92F |
\p{IsRejang} | U+A930 to U+A95F |
\p{IsHangulJamoExtended-A} | U+A960 to U+A97F |
\p{IsJavanese} | U+A980 to U+A9DF |
\p{IsMyanmarExtended-B} | U+A9E0 to U+A9FF |
\p{IsCham} | U+AA00 to U+AA5F |
\p{IsMyanmarExtended-A} | U+AA60 to U+AA7F |
\p{IsTaiViet} | U+AA80 to U+AADF |
\p{IsMeeteiMayekExtensions} | U+AAE0 to U+AAFF |
\p{IsEthiopicExtended-A} | U+AB00 to U+AB2F |
\p{IsLatinExtended-E} | U+AB30 to U+AB6F |
\p{IsCherokeeSupplement} | U+AB70 to U+ABBF |
\p{IsMeeteiMayek} | U+ABC0 to U+ABFF |
\p{IsHangulSyllables} | U+AC00 to U+D7AF |
\p{IsHangulJamoExtended-B} | U+D7B0 to U+D7FF |
\p{IsHighSurrogates} | U+D800 to U+DB7F |
\p{IsHighPrivateUseSurrogates} | U+DB80 to U+DBFF |
\p{IsLowSurrogates} | U+DC00 to U+DFFF |
\p{IsPrivateUseArea} | U+E000 to U+F8FF |
\p{IsCJKCompatibilityIdeographs} | U+F900 to U+FAFF |
\p{IsAlphabeticPresentationForms} | U+FB00 to U+FB4F |
\p{IsArabicPresentationForms-A} | U+FB50 to U+FDFF |
\p{IsVariationSelectors} | U+FE00 to U+FE0F |
\p{IsVerticalForms} | U+FE10 to U+FE1F |
\p{IsCombiningHalfMarks} | U+FE20 to U+FE2F |
\p{IsCJKCompatibilityForms} | U+FE30 to U+FE4F |
\p{IsSmallFormVariants} | U+FE50 to U+FE6F |
\p{IsArabicPresentationForms-B} | U+FE70 to U+FEFF |
\p{IsHalfwidthandFullwidthForms} | U+FF00 to U+FFEF |
\p{IsSpecials} | U+FFF0 to U+FFFF |
\p{IsLinearBSyllabary} | U+10000 to U+1007F |
\p{IsLinearBIdeograms} | U+10080 to U+100FF |
\p{IsAegeanNumbers} | U+10100 to U+1013F |
\p{IsAncientGreekNumbers} | U+10140 to U+1018F |
\p{IsAncientSymbols} | U+10190 to U+101CF |
\p{IsPhaistosDisc} | U+101D0 to U+101FF |
\p{IsLycian} | U+10280 to U+1029F |
\p{IsCarian} | U+102A0 to U+102DF |
\p{IsCopticEpactNumbers} | U+102E0 to U+102FF |
\p{IsOldItalic} | U+10300 to U+1032F |
\p{IsGothic} | U+10330 to U+1034F |
\p{IsOldPermic} | U+10350 to U+1037F |
\p{IsUgaritic} | U+10380 to U+1039F |
\p{IsOldPersian} | U+103A0 to U+103DF |
\p{IsDeseret} | U+10400 to U+1044F |
\p{IsShavian} | U+10450 to U+1047F |
\p{IsOsmanya} | U+10480 to U+104AF |
\p{IsOsage} | U+104B0 to U+104FF |
\p{IsElbasan} | U+10500 to U+1052F |
\p{IsCaucasianAlbanian} | U+10530 to U+1056F |
\p{IsVithkuqi} | U+10570 to U+105BF |
\p{IsLinearA} | U+10600 to U+1077F |
\p{IsLatinExtended-F} | U+10780 to U+107BF |
\p{IsCypriotSyllabary} | U+10800 to U+1083F |
\p{IsImperialAramaic} | U+10840 to U+1085F |
\p{IsPalmyrene} | U+10860 to U+1087F |
\p{IsNabataean} | U+10880 to U+108AF |
\p{IsHatran} | U+108E0 to U+108FF |
\p{IsPhoenician} | U+10900 to U+1091F |
\p{IsLydian} | U+10920 to U+1093F |
\p{IsMeroiticHieroglyphs} | U+10980 to U+1099F |
\p{IsMeroiticCursive} | U+109A0 to U+109FF |
\p{IsKharoshthi} | U+10A00 to U+10A5F |
\p{IsOldSouthArabian} | U+10A60 to U+10A7F |
\p{IsOldNorthArabian} | U+10A80 to U+10A9F |
\p{IsManichaean} | U+10AC0 to U+10AFF |
\p{IsAvestan} | U+10B00 to U+10B3F |
\p{IsInscriptionalParthian} | U+10B40 to U+10B5F |
\p{IsInscriptionalPahlavi} | U+10B60 to U+10B7F |
\p{IsPsalterPahlavi} | U+10B80 to U+10BAF |
\p{IsOldTurkic} | U+10C00 to U+10C4F |
\p{IsOldHungarian} | U+10C80 to U+10CFF |
\p{IsHanifiRohingya} | U+10D00 to U+10D3F |
\p{IsRumiNumeralSymbols} | U+10E60 to U+10E7F |
\p{IsYezidi} | U+10E80 to U+10EBF |
\p{IsOldSogdian} | U+10F00 to U+10F2F |
\p{IsSogdian} | U+10F30 to U+10F6F |
\p{IsOldUyghur} | U+10F70 to U+10FAF |
\p{IsChorasmian} | U+10FB0 to U+10FDF |
\p{IsElymaic} | U+10FE0 to U+10FFF |
\p{IsBrahmi} | U+11000 to U+1107F |
\p{IsKaithi} | U+11080 to U+110CF |
\p{IsSoraSompeng} | U+110D0 to U+110FF |
\p{IsChakma} | U+11100 to U+1114F |
\p{IsMahajani} | U+11150 to U+1117F |
\p{IsSharada} | U+11180 to U+111DF |
\p{IsSinhalaArchaicNumbers} | U+111E0 to U+111FF |
\p{IsKhojki} | U+11200 to U+1124F |
\p{IsMultani} | U+11280 to U+112AF |
\p{IsKhudawadi} | U+112B0 to U+112FF |
\p{IsGrantha} | U+11300 to U+1137F |
\p{IsNewa} | U+11400 to U+1147F |
\p{IsTirhuta} | U+11480 to U+114DF |
\p{IsSiddham} | U+11580 to U+115FF |
\p{IsModi} | U+11600 to U+1165F |
\p{IsMongolianSupplement} | U+11660 to U+1167F |
\p{IsTakri} | U+11680 to U+116CF |
\p{IsAhom} | U+11700 to U+1174F |
\p{IsDogra} | U+11800 to U+1184F |
\p{IsWarangCiti} | U+118A0 to U+118FF |
\p{IsDivesAkuru} | U+11900 to U+1195F |
\p{IsNandinagari} | U+119A0 to U+119FF |
\p{IsZanabazarSquare} | U+11A00 to U+11A4F |
\p{IsSoyombo} | U+11A50 to U+11AAF |
\p{IsUnifiedCanadianAboriginalSyllabicsExtended-A} | U+11AB0 to U+11ABF |
\p{IsPauCinHau} | U+11AC0 to U+11AFF |
\p{IsBhaiksuki} | U+11C00 to U+11C6F |
\p{IsMarchen} | U+11C70 to U+11CBF |
\p{IsMasaramGondi} | U+11D00 to U+11D5F |
\p{IsGunjalaGondi} | U+11D60 to U+11DAF |
\p{IsMakasar} | U+11EE0 to U+11EFF |
\p{IsLisuSupplement} | U+11FB0 to U+11FBF |
\p{IsTamilSupplement} | U+11FC0 to U+11FFF |
\p{IsCuneiform} | U+12000 to U+123FF |
\p{IsCuneiformNumbersandPunctuation} | U+12400 to U+1247F |
\p{IsEarlyDynasticCuneiform} | U+12480 to U+1254F |
\p{IsCypro-Minoan} | U+12F90 to U+12FFF |
\p{IsEgyptianHieroglyphs} | U+13000 to U+1342F |
\p{IsEgyptianHieroglyphFormatControls} | U+13430 to U+1343F |
\p{IsAnatolianHieroglyphs} | U+14400 to U+1467F |
\p{IsBamumSupplement} | U+16800 to U+16A3F |
\p{IsMro} | U+16A40 to U+16A6F |
\p{IsTangsa} | U+16A70 to U+16ACF |
\p{IsBassaVah} | U+16AD0 to U+16AFF |
\p{IsPahawhHmong} | U+16B00 to U+16B8F |
\p{IsMedefaidrin} | U+16E40 to U+16E9F |
\p{IsMiao} | U+16F00 to U+16F9F |
\p{IsIdeographicSymbolsandPunctuation} | U+16FE0 to U+16FFF |
\p{IsTangut} | U+17000 to U+187FF |
\p{IsTangutComponents} | U+18800 to U+18AFF |
\p{IsKhitanSmallScript} | U+18B00 to U+18CFF |
\p{IsTangutSupplement} | U+18D00 to U+18D7F |
\p{IsKanaExtended-B} | U+1AFF0 to U+1AFFF |
\p{IsKanaSupplement} | U+1B000 to U+1B0FF |
\p{IsKanaExtended-A} | U+1B100 to U+1B12F |
\p{IsSmallKanaExtension} | U+1B130 to U+1B16F |
\p{IsNushu} | U+1B170 to U+1B2FF |
\p{IsDuployan} | U+1BC00 to U+1BC9F |
\p{IsShorthandFormatControls} | U+1BCA0 to U+1BCAF |
\p{IsZnamennyMusicalNotation} | U+1CF00 to U+1CFCF |
\p{IsByzantineMusicalSymbols} | U+1D000 to U+1D0FF |
\p{IsMusicalSymbols} | U+1D100 to U+1D1FF |
\p{IsAncientGreekMusicalNotation} | U+1D200 to U+1D24F |
\p{IsMayanNumerals} | U+1D2E0 to U+1D2FF |
\p{IsTaiXuanJingSymbols} | U+1D300 to U+1D35F |
\p{IsCountingRodNumerals} | U+1D360 to U+1D37F |
\p{IsMathematicalAlphanumericSymbols} | U+1D400 to U+1D7FF |
\p{IsSuttonSignWriting} | U+1D800 to U+1DAAF |
\p{IsLatinExtended-G} | U+1DF00 to U+1DFFF |
\p{IsGlagoliticSupplement} | U+1E000 to U+1E02F |
\p{IsNyiakengPuachueHmong} | U+1E100 to U+1E14F |
\p{IsToto} | U+1E290 to U+1E2BF |
\p{IsWancho} | U+1E2C0 to U+1E2FF |
\p{IsEthiopicExtended-B} | U+1E7E0 to U+1E7FF |
\p{IsMendeKikakui} | U+1E800 to U+1E8DF |
\p{IsAdlam} | U+1E900 to U+1E95F |
\p{IsIndicSiyaqNumbers} | U+1EC70 to U+1ECBF |
\p{IsOttomanSiyaqNumbers} | U+1ED00 to U+1ED4F |
\p{IsArabicMathematicalAlphabeticSymbols} | U+1EE00 to U+1EEFF |
\p{IsMahjongTiles} | U+1F000 to U+1F02F |
\p{IsDominoTiles} | U+1F030 to U+1F09F |
\p{IsPlayingCards} | U+1F0A0 to U+1F0FF |
\p{IsEnclosedAlphanumericSupplement} | U+1F100 to U+1F1FF |
\p{IsEnclosedIdeographicSupplement} | U+1F200 to U+1F2FF |
\p{IsMiscellaneousSymbolsandPictographs} | U+1F300 to U+1F5FF |
\p{IsEmoticons} | U+1F600 to U+1F64F |
\p{IsOrnamentalDingbats} | U+1F650 to U+1F67F |
\p{IsTransportandMapSymbols} | U+1F680 to U+1F6FF |
\p{IsAlchemicalSymbols} | U+1F700 to U+1F77F |
\p{IsGeometricShapesExtended} | U+1F780 to U+1F7FF |
\p{IsSupplementalArrows-C} | U+1F800 to U+1F8FF |
\p{IsSupplementalSymbolsandPictographs} | U+1F900 to U+1F9FF |
\p{IsChessSymbols} | U+1FA00 to U+1FA6F |
\p{IsSymbolsandPictographsExtended-A} | U+1FA70 to U+1FAFF |
\p{IsSymbolsforLegacyComputing} | U+1FB00 to U+1FBFF |
\p{IsCJKUnifiedIdeographsExtensionB} | U+20000 to U+2A6DF |
\p{IsCJKUnifiedIdeographsExtensionC} | U+2A700 to U+2B73F |
\p{IsCJKUnifiedIdeographsExtensionD} | U+2B740 to U+2B81F |
\p{IsCJKUnifiedIdeographsExtensionE} | U+2B820 to U+2CEAF |
\p{IsCJKUnifiedIdeographsExtensionF} | U+2CEB0 to U+2EBEF |
\p{IsCJKCompatibilityIdeographsSupplement} | U+2F800 to U+2FA1F |
\p{IsCJKUnifiedIdeographsExtensionG} | U+30000 to U+3134F |
\p{IsTags} | U+E0000 to U+E007F |
\p{IsVariationSelectorsSupplement} | U+E0100 to U+E01EF |
\p{IsSupplementaryPrivateUseArea-A} | U+F0000 to U+FFFFF |
\p{IsSupplementaryPrivateUseArea-B} | U+100000 to U+10FFFF |
In addition, the −−unicode option enables standard Unicode language scripts:
\p{Adlam}, \p{Ahom}, \p{Anatolian_Hieroglyphs}, \p{Arabic}, \p{Armenian}, \p{Avestan}, \p{Balinese}, \p{Bamum}, \p{Bassa_Vah}, \p{Batak}, \p{Bengali}, \p{Bhaiksuki}, \p{Bopomofo}, \p{Brahmi}, \p{Braille}, \p{Buginese}, \p{Buhid}, \p{Canadian_Aboriginal}, \p{Carian}, \p{Caucasian_Albanian}, \p{Chakma}, \p{Cham}, \p{Cherokee}, \p{Chorasmian}, \p{Common}, \p{Coptic}, \p{Cuneiform}, \p{Cypriot}, \p{Cypro_Minoan}, \p{Cyrillic}, \p{Deseret}, \p{Devanagari}, \p{Dives_Akuru}, \p{Dogra}, \p{Duployan}, \p{Egyptian_Hieroglyphs}, \p{Elbasan}, \p{Elymaic}, \p{Ethiopic}, \p{Georgian}, \p{Glagolitic}, \p{Gothic}, \p{Grantha}, \p{Greek}, \p{Gujarati}, \p{Gunjala_Gondi}, \p{Gurmukhi}, \p{Han}, \p{Hangul}, \p{Hanifi_Rohingya}, \p{Hanunoo}, \p{Hatran}, \p{Hebrew}, \p{Hiragana}, \p{Imperial_Aramaic}, \p{Inscriptional_Pahlavi}, \p{Inscriptional_Parthian}, \p{Javanese}, \p{Kaithi}, \p{Kannada}, \p{Katakana}, \p{Kayah_Li}, \p{Kharoshthi}, \p{Khitan_Small_Script}, \p{Khmer}, \p{Khojki}, \p{Khudawadi}, \p{Lao}, \p{Latin}, \p{Lepcha}, \p{Limbu}, \p{Linear_A}, \p{Linear_B}, \p{Lisu}, \p{Lycian}, \p{Lydian}, \p{Mahajani}, \p{Makasar}, \p{Malayalam}, \p{Mandaic}, \p{Manichaean}, \p{Marchen}, \p{Masaram_Gondi}, \p{Medefaidrin}, \p{Meetei_Mayek}, \p{Mende_Kikakui}, \p{Meroitic_Cursive}, \p{Meroitic_Hieroglyphs}, \p{Miao}, \p{Modi}, \p{Mongolian}, \p{Mro}, \p{Multani}, \p{Myanmar}, \p{Nabataean}, \p{Nandinagari}, \p{New_Tai_Lue}, \p{Newa}, \p{Nko}, \p{Nushu}, \p{Nyiakeng_Puachue_Hmong}, \p{Ogham}, \p{Old_Uyghur}, \p{Ol_Chiki}, \p{Old_Hungarian}, \p{Old_Italic}, \p{Old_North_Arabian}, \p{Old_Permic}, \p{Old_Persian}, \p{Old_Sogdian}, \p{Old_South_Arabian}, \p{Old_Turkic}, \p{Oriya}, \p{Osage}, \p{Osmanya}, \p{Pahawh_Hmong}, \p{Palmyrene}, \p{Pau_Cin_Hau}, \p{Phags_Pa}, \p{Phoenician}, \p{Psalter_Pahlavi}, \p{Rejang}, \p{Runic}, \p{Samaritan}, \p{Saurashtra}, \p{Sharada}, \p{Shavian}, \p{Siddham}, \p{SignWriting}, \p{Sinhala}, \p{Sogdian}, \p{Sora_Sompeng}, \p{Soyombo}, \p{Sundanese}, \p{Syloti_Nagri}, \p{Syriac}, \p{Tagalog}, \p{Tagbanwa}, \p{Tai_Le}, \p{Tai_Tham}, \p{Tai_Viet}, \p{Takri}, \p{Tamil}, \p{Tangut}, \p{Tangsa}, \p{Telugu}, \p{Thaana}, \p{Thai}, \p{Tibetan}, \p{Tifinagh}, \p{Tirhuta}, \p{Toto}, \p{Ugaritic}, \p{Vai}, \p{Vithkuqi}, \p{Wancho}, \p{Warang_Citi}, \p{Yezidi}, \p{Yi}, \p{Zanabazar_Square},
\p{Greek} class represents Greek and Coptic letters and differs from the Unicode block \p{IsGreek} that spans a specific Unicode block of Greek and Coptic characters only, which also includes unassigned characters.Anchors are used to demarcate the start and end of input or the start and end of a line:
| Pattern | Matches |
|---|---|
^φ | matches φ at the start of input or start of a line (multi-line mode) |
φ$ | matches φ at the end of input or end of a line (multi-line mode) |
\Aφ | matches φ at the start of input |
φ\z | matches φ at the end of input |
Anchors in lexer specifications require pattern context, meaning that φ cannot be empty.
Note that <<EOF>> in lexer specifications match the end of input, which can be used in place of the pattern \z.
Actions for the start of input can be specified in an initial code block preceding the rules, see Initial code blocks .
Word boundaries demarcate words. Word characters are letters, digits, and the underscore.
| Pattern | Matches |
|---|---|
\bφ | matches φ starting at a word boundary |
φ\b | matches φ ending at a word boundary |
\Bφ | matches φ starting at a non-word boundary |
φ\B | matches φ ending at a non-word boundary |
\<φ | matches φ that starts as a word |
\>φ | matches φ that starts as a non-word |
φ\< | matches φ that ends as a non-word |
φ\> | matches φ that ends as a word |
Automatic indent and dedent matching is a special feature of RE/flex and is only available when the RE/flex matcher engine is used (the default matcher). An indent and a dedent position is defined and matched with:
| Pattern | Matches |
|---|---|
\i | indent: matches and adds a new indent stop position |
\j | dedent: matches a previous indent position, removes one indent stop |
The \i and \j anchors should be used in combination with the start of a line anchor ^ followed by a pattern that represents left margin spacing for indentations, followed by a \i or a \j at the end of the pattern. The margin spacing pattern may include any characters that are considered part of the left margin, but should exclude \n. For example:
The \h pattern matches space and tabs, where tabs advance to the next column that is a multiple of 8. The tab multiplier can be changed by setting the −−tabs=N option where N must be 1 (no expansion), 2, 4, or 8. The tabs value can be changed at runtime with matcher().tabs(N):
| RE/flex action | Result |
|---|---|
matcher().tabs() | returns the current tabs value 1, 2, 4, or 8 |
matcher().tabs(n) | set the tabs value n where n is 1, 2, 4, or 8 |
Using negative patterns of the form (?^φ) where φ is a regex pattern that is consumed but never returned by the matcher as pattern match, see Negative patterns, we can ignore empty lines and multi-line comments that would otherwise affect indent stops:
Likewise, we can add rules to ignore inline //-comments to our lexer specification. To do so, we should add a rule with pattern (?^^\h*"//".*) to ignore //-comments without affecting stop positions.
To scan input that continues on the next new line(s) (which may affect indent stops) while preserving the current indent stop positions, use the RE/flex matcher matcher().push_stops() and matcher().pop_stops(), or matcher().stops() to directlye access the vector of indent stops to modify:
| RE/flex action | Result |
|---|---|
matcher().push_stops() | push indent stops on the stack then clear stops |
matcher().pop_stops() | pop indent stops and make them current |
matcher().clear_stops() | clear current indent stops |
matcher().stops() | reference to current std::vector<size_t> stops |
matcher().last_stop() | returns the last indent stop position or 0 |
matcher().insert_stop(n) | inserts/appends an indent stop at position n |
matcher().delete_stop(n) | remove stop positions from position n and up |
For example, to continue scanning after a /* for multiple lines without indentation matching, allowing for possible nested /*-comments, up to a */ you can save the current indent stop positions and transition to a new start condition state to scan the content between /* and */:
The multi-line comments enclosed in /* */ are processed by the exclusive COMMENT start condition rules. The rules allow for /*-comment nesting. We use stops = matcher().stops() and matcher().stops() = stops to save and restore stops.
In this example we added rules so that comments on a line do not affect the current indent stops. This is done by using the negative pattern (?^^\h+/"/*") with a trailing context /"/*". Here we used a negative pattern to eat the margin spacing without affecting indent stops. The trailing context looks ahead for a /* but does not consume the /*.
However, when a /*-comment starts at the first column of a line, the pattern (?^^\h+/"/*") does not match it, even when we change it to (?^^\h*/"/*"). This is because the \h* cannot be an empty match since the trailing context does not return a match, and matches cannot be empty. Therefore, adding the rule with pattern ^"/*"\j adjusts for that, but accepting the dedents caused by the /*-comment. This is fine, because the stop positions are restored after scanning the /*-comment.
We added the negative pattern (?^^\h*\n) to ignore empty lines. This allows empty lines in the input without affecting indent stops.
matcher().stops() method to access the vector of stops to modify, we must make sure to keep the stop positions in the vector sorted.In addition to the \i and \j indent and dedent anchors, the \k undent anchor matches when the indent depth changed (before the position of \k), undoing this change to keep the current indent stops ("undenting"):
| Pattern | Matches |
|---|---|
\k | undent: matches when indent depth changed, keep current indent stops |
The example shown above can be simplified with \k. We no longer need to explicitly save and restore indent stops in a variable:
The pattern \h*"/*"\k? matches a /*-comment with leading white space. The \k anchor matches if the indent depth changed in the leading white space, which is also matched by the first three patterns in the lexer specification before their \i and \j indent and dedent anchors, respectively. If the indent depth changed, the \k anchor matches, while keeping the current indent stops unchanged by undoing these changes. Because we also want to match \* when the indent depth does not change, we made \k optional in pattern \h*"/*"\k?. The anchor ^ is not used here either, since comments after any spacing should be matched. Alternatively, two patterns ^\h*"/*"\k and \h*"/*" may be used, where the first matches if and only if the indent stops changed on a new line and were undone.
Note that the COMMENT rules do not use \i or \j. This means that the current indent stops are never matched or changed and remain the same as in the INITIAL state, when returning to the INITIAL state.
Another use of \k is to ignore indents to only detect a closing dedent with \j. For example, when comments are allowed to span multiple lines when indented below the start of the # comment:
The COMMENT state checks for an indent to switch to state MORECOM, which eats the indented comment block. When there is no indent .|\n is matched, i.e. something must be matched. This match is put back into the input with matcher().less(0) (or yyless(0) with −−flex).
Alternatively, the indent level in the COMMENT rules could be tracked by incrementing a variable when matching \i and decrementing the variable when matching \j until the variable is zero at the final dedent.
\i, \j, and \k should appear at the end of a regex pattern.See Start condition states for more information about start condition states. See Negative patterns for more information on negative patterns.
When negative regex patterns of the form (?^φ) match, they are simply ignored by the matcher and never returned as pattern matches. They are useful to return matches for some given pattern except when this pattern is more specific and should be ignored in the input. For example, to match any sequence of digits except digits starting with a zero the pattern \d+|(?^0\d+) can be used instead of [1-9]\d+. While these two patterns may look similar at first glance, these two patterns differ in that the first pattern (with the negative sub-pattern (?^0\d+)) ignores numbers with leading zeros such as 012 while the second pattern will match the 12 in 012.
As another example, say we are searching for a given word while ignoring occurrences of the word in quoted strings. We can use the pattern word|(?^".*?") for this, where (?^".*?") matches all quoted strings that we want to ignore (to skip C/C++ quoted strings in source code input files, use the longer pattern (?^"(\\\\.|\\\\\\r?\\n|[^\\\\\\n"])*")).
A negative pattern can also be used to consume line continuations without affecting the indentation stops defined by indent marker \i. Negative patterns are a RE/flex feature. For example:
The negative pattern (?^\\\n\h+) consumes input internally as if we are repeatedly calling input() (or yyinput() with −−flex). We used it here to consume the line-ending \ and the indent that followed it, as if this text was not part of the input, which ensures that the current indent positions defined by \i are not affected. See Indent/nodent/dedent for more details on indentation matching.
X(?^Y) equals (?^XY) and the pattern (?^Y)Z equals (?^YZ). At least one character should be matched in a negative pattern for the pattern to be effective. For example, X(?^Y)? matches X but not XY, which is the same as X|(?^XY).A lookahead pattern φ(?=ψ) matches φ only when followed by pattern ψ. The text matched by ψ is not consumed.
Boost.Regex and PCRE2 matchers support lookahead φ(?=ψ) and lookbehind φ(?<=ψ) patterns that may appear anywhere in a regex. The RE/flex matcher supports lookahead at the end of a pattern, similar to Trailing context.
A lookbehind pattern φ(?<=ψ) matches φ only when it also matches pattern ψ at its end (that is, .*(?<=ab) matches anything that ends in ab).
The RE/flex matcher does not support lookbehind. Lookbehind patterns should not look too far behind, see Limitations .
Flex "trailing context" φ/ψ matches a pattern φ only when followed by the lookahead pattern ψ. A trailing context φ/ψ has the same meaning as the lookahead φ(?=ψ), see Lookahead.
A trailing context can only be used in lexer specifications and should only occur at the end of a pattern, not in the middle of a pattern. There are some important Limitations to consider that are historical and related to the construction of efficient FSMs for regular expressions. The limitations apply to trailing context and lookaheads that the RE/flex matcher implements.
Use reflex option −−unicode (or %option unicode) to globally enable Unicode. Use (?u:φ) to locally enable Unicode in a pattern φ. Use (?-u:φ) to locally disable Unicode in φ. Unicode mode enables the following patterns to be used:
| Pattern | Matches |
|---|---|
. | matches any character (or byte in Unicode mode, see Invalid UTF encodings and the dot pattern ) |
€ (UTF-8) | matches wide character €, encoded in UTF-8 |
[€¥£] (UTF-8) | matches wide character €, ¥ or £, encoded in UTF-8 |
\X | matches any ISO-8859-1 or Unicode character |
\R | matches a Unicode line break \r\n or [\u{000A}-\u{000D}u{U+0085}\u{2028}\u{2029}] |
\s | matches a white space character [ \t\n\v\f\r\p{Z}] |
\l | matches a lower case letter with Unicode sub-property Ll |
\u | matches an upper case letter with Unicode sub-property Lu |
\w | matches a Unicode word character with property L, Nd, or Pc |
\u{20AC} | matches Unicode character U+20AC |
\p{C} | matches a character in category C |
\p{^C},\P{C} | matches any character except in category C |
When converting regex patterns for use with a C++ regex library, use regex matcher converter flag reflex::convert_flag::unicode to convert Unicode patterns for use with the 8-bit based RE/flex, Boost.Regex, PCRE2, and std::regex regex libraries, see Regex converters for more details.
Free space mode can be useful to improve readability of patterns. Free space mode permits spacing between concatenations and alternations in patterns. To to match a single space use [ ], to match a tab use [\t], to match either use \h. Long patterns may continue on the next line when the line ends with an escape \. Comments are ignored in patterns in free-space mode. Comments start with a # and end at the end of the line. To specify a # use [#].
In addition, /*...*/ comments are permitted in lexer specifications in free-space mode when the −−matcher=reflex option is specified (the default matcher).
Free space mode requires lexer actions in The rules section of a lexer specification to be placed in { } blocks and user code to be placed in %{ %} blocks instead of indented.
To enable free space mode in reflex use the −−freespace option (or %option freespace).
Prepend (?x) to the regex to specify free-space mode or use (?x:φ) to locally enable free-space mode in the sub-pattern φ. Use (?-x:φ) to locally disable free-space mode in φ. The regex pattern may require conversion when the regex library does not support free-space mode modifiers, see Regex converters for more details.
Multi-line mode makes the anchors ^ and $ match the start and end of a line, respectively. Multi-line mode is the default mode in lexer specifications.
Prepend (?m) to the regex to specify multi-line mode or use (?m:φ) to locally enable multi-line mode in the sub-pattern φ. Use (?-m:φ) to locally disable multi-line mode in φ.
To enable dotall mode in reflex use the -a or −−dotall option (or %option dotall).
Prepend (?s) to the regex to specify dotall mode or use (?s:φ) to locally enable dotall mode in the sub-pattern φ. Use (?-s:φ) to locally disable dotall mode in φ. The regex pattern may require conversion when the regex library does not support dotall mode modifiers, see Regex converters for more details.
To enable case-insensitive mode in reflex use the -i or −−case-insensitive option (or %option case-insensitive).
Prepend (?i) to the regex to specify case-insensitive mode or use (?i:φ) to locally enable case-insensitive mode in the sub-pattern φ. Use (?-i:φ) to locally disable case-insensitive mode in φ. The regex pattern may require conversion when the regex library does not support non-ASCII Unicode case-insensitive mode modifiers, see Regex converters for more details.
Multiple (?i:φ) Case-insensitive mode, (?m:φ) Multi-line mode, (?s:φ) Dotall mode, (?u:φ) Unicode mode, and (?x:φ) Free space mode modifiers may be applied to the same pattern φ by combining them in one inline modifier (?imsux-imsux:φ), where the mode modifiers before the dash are enabled and the mode modifiers after the dash are disabled.
The PCRE and Boost regex libraries support group captures. This feature can be used with RE/flex using named captures. Only named captures can be used and the names must be unique among all lexer patterns, because a single regex pattern is compiled that combines all lexer rules (numeric group captures would apply globally across all rules, which is confusing.) For PCRE, Perl matching is required since PCRE POSIX matching does not support group captures. A named group is defined with (?<name>pattern) and back-referenced with \g{name}. The subpattern matched by a name can be retrieved in a lexer rule as follows:
See also POSIX versus Perl matching .
By default, reflex produces a Lexer class with a virtual lex scanner function. The name of this function as well as the Lexer class name and the namespace can be set with options:
| Option | RE/flex default name | Flex default name |
|---|---|---|
namespace | n/a | n/a |
lexer | Lexer class | yyFlexLexer class |
lex | lex() function | yylex() function |
To customize the Lexer class use these options and code injection.
You can declare multiple nested namespace names by namespace=NAME1::NAME2::NAME3, or by separating the names with a dot such as namespace=NAME1.NAME2.NAME3, to declare the lexer in NAME1::NAME2::NAME3.
To understand the impact of these options, consider the following lex specification template with upper case names represening the parts specified by the user:
This produces the following Lexer class with the template parts filled in:
The Lexer class produced with option −−flex is compatible with Flex (assuming Flex with option -+ for C++):
To use a custom lexer class that inherits the generated base Lexer class, use option −−class=NAME to declare the name of your custom lexer class (or option −−yyclass=NAME to also enable −−flex compatibility with the yyFlexLexer class). For details, see Inheriting Lexer/yyFlexLexer .
To define a custom lexer class that inherits the generated Lexer or the yyFlexLexer class, use option −−class=NAME or option −−yyclass=NAME, respectively. Note that −−yyclass=NAME also enables option −−flex and therefore enables Flex specification syntax.
When a −−class=NAME or −−yyclass=NAME option is specified with the name of your custom lexer class, reflex generates the lex() (or yylex()) method code for your custom lexer class. The custom lexer class should declare a public int lex() method (or int yylex() method with option −−yyclass=NAME). Otherwise, C++ compilation of your custom class will fail.
For example, the following bare-bones custom Lexer class definition simply inherits Lexer and declares a public int lex() method:
The int MyLexer::lex() method code is generated by reflex for this lexer specification.
Options −−lexer=NAME and −−lex=NAME may be combined with −−class=NAME to change the name of the inherited Lexer class and change the name of the lex() method, respectively.
When using option −−yyclass=NAME the inherited lexer is yyFlexLexer. The custom lexer class should declare a public yylex() method similar to Flex. For example:
The int MyLexer::yylex() method code is generated by reflex for this lexer specification.
To rename a lexer class to combine multiple lexers in one application, use the −−lexer=NAME option. This option renames the generated lexer class to avoid lexer class name clashes. Use this option in combination with option −−header-file to output a header file with the lexer class declaration to include in your application source code.
In addition, use option −−prefix=NAME to output the generated code in file lex.NAME.cpp instead of the standard lex.yy.cpp to avoid name clashes. This option also affect the −−flex option by generating xxFlexLexer with a xxlex() method when option −−prefix=xx is specified. The generated #define names (some of which are added to support option −−flex) are prefixed to avoid macro name clashes.
Alternatively to −−lexer=NAME and −−prefix=NAME, you can use −−namespace=NAME to place the generated lexer class in a C++ namespace to avoid lexer class name clashes. Note that unlike the −−prefix=NAME option, the generated file names are not renamed by including NAME in the filename. Generate the files in a separate subdirectory for each C++ namespace specified with −−namespace=NAME. Or you can explicitly specify the lex filename with −−outfile=NAME and also −−header-file=NAME and `−−tables-file=NAME when header files and table files are used.
To create a Lexer class instance that reads from a designated input source instead of standard input, pass the input source as the first argument to its constructor and use the second argument to optionally set an std::ostream that is assigned to out() and is used by echo() (likewise, assigned to *yyout and used by ECHO when option −−flex is specified):
likewise, with option −−flex:
where input is a reflex::Input object. The reflex::Input constructor takes a FILE* descriptor, std::istream, a string std::string or const char*, or a wide string std::wstring or const wchar_t*.
std::string and char* strings. The lexer reads the specified input while scanning the input with subsequent lex() (and yylex() etc.) calls. The input source is copied in chunks of bytes to an internal buffer, depending on the buffering mode.The following methods are available to specify an input source:
| RE/flex action | Flex action | Result |
|---|---|---|
in() | *yyin | get pointer to current reflex::Input i |
in() = i | yyin = &i | set input reflex::Input i |
in(i) | yyrestart(i) | reset and scan input from reflex::Input i |
in(s) | yy_scan_string(s) | reset and scan string s (std::string or char*) |
in(s) | yy_scan_wstring(s) | reset and scan wide string s (std::wstring or wchar_t*) |
in(b, n) | yy_scan_bytes(b, n) | reset and scan n bytes at address b (buffered) |
buffer(b, n+1) | yy_scan_buffer(b, n+2) | reset and scan n bytes at address b (zero copy) |
For example, to switch input to another source while using the scanner, use in(i) with reflex::Input i as an argument:
You can assign new input with in() = i, which does not reset the lexer's matcher. This means that when the end of the input (EOF) is reached, and you want to switch to new input, then you should clear the EOF state first with lexer.matcher().set_end(false) to reset EOF. Or use lexer.matcher().reset() to clear the state.
Invoking in(i) resets the lexer's matcher (i.e. internally with matcher.reset()). This clears the line and column counters, resets the internal anchor and boundary flags for anchor and word boundary matching, and resets the matcher to consume buffered input.
These in(i) operations specify strings and bytes that are copied to an internal buffer. This is desirable, because the scanner uses a matcher that initializes a buffer, block-wise copies more input to this internal buffer on demand, and modifies this buffered content, e.g. to allow text() to return a 0-terminated char string. Zero copy overhead is obtained with lexer method buffer(b, n) to assign an external buffer:
buffer(b, n) scans n-1 bytes at address b. The length n should include the final zero byte at the end of the string.With options −−flex and −−bison you can also use classic Flex functions:
The yy_scan_string, yy_scan_bytes, and yy_scan_wstring functions create a new buffer (i.e. a new matcher in RE/flex) and replace the old buffer without deleting it. A pointer to the new buffer is returned, which becomes the new YY_CURRENT_BUFFER. You should delete the old buffer with yy_delete_buffer(YY_CURRENT_BUFFER) before creating a new buffer.
Zero copy overhead is obtained with yy_scan_buffer(b, n):
yy_scan_buffer(b, n) (when option −−flex is used) scans n-2 bytes at address b. The length n should include two final zero bytes at the end!yy_scan_buffer(b, n) only touches the first final byte and not the second byte, since this function is the same as calling buffer(b, n-1). In fact, the specified string may have any final byte value. The final byte of the string will be set to zero when text() (or yytext) or rest() are used. But otherwise the final byte remains completely untouched by the other lexer functions, including echo() (and Flex-compatible ECHO). Only unput(c), wunput(), text() (or yytext), rest(), and span() modify the buffer contents, where text() and rest() require an extra byte at the end of the buffer to make the strings returned by these functions 0-terminated. This means that you can scan read-only memory of n bytes located at address b by using buffer(b, n+1) safely, for example to read read-only mmap(2) PROT_READ memory, as long as unput(c),wunput(), text() (or yytext), rest(), and span() are not used.The Flex yy_scan_string, yy_scan_bytes, yy_scan_wstring, and yy_scan_buffer functions take an extra last yyscan_t argument for reentrant scanners generated with option −−reentrant, for example:
The yyscanner macro is essentially the same is the this pointer that can only be used in lexer methods and in lexer rules. Outside the scope of lexer methods a pointer to your yyFlexLexer lexer object should be used instead, for example yyget_in(&lexer). Also YY_CURRENT_BUFFER should be replaced by yyget_current_buffer(&lexer). See also Reentrant scanners.
Switching input before the end of the input source is reached discards all remaining input from that source. To switch input without affecting the current input source, switch matchers instead. The matchers buffer the input and manage the input state, in addition to pattern matching the input.
The following methods are available to specify a matcher Matcher m (a Flex "buffer") for a lexer:
| RE/flex action | Flex action | Result |
|---|---|---|
matcher(m) | yy_switch_to_buffer(m) | use matcher m |
new_matcher(i) | yy_create_buffer(i, n) | returns new matcher for reflex::Input i |
del_matcher(m) | yy_delete_buffer(m) | delete matcher m |
push_matcher(m) | yypush_buffer_state(m) | push current matcher, then use m |
pop_matcher() | yypop_buffer_state() | pop matcher and delete current |
ptr_matcher() | YY_CURRENT_BUFFER | pointer to current matcher |
has_matcher() | YY_CURRENT_BUFFER != 0 | current matcher is usable |
For example, to switch to a matcher that scans from a new input source, then restores the old input source:
the same with the −−flex option becomes:
This switches the scanner's input by switching to another matcher. Note that matcher(m) may be used by the virtual wrap() method (or yywrap() when option −−flex is specified) if you use input wrapping after EOF to set things up for continued scanning.
Switching input sources (via either matcher(m), in(i), or the Flex functions) does not change the current start condition state.
When the scanner reaches the end of the input, it will check the int wrap() method to detetermine if scanning should continue. If wrap() returns one (1) the scanner terminates and returns zero to its caller. If wrap() returns zero (0) then the scanner continues. In this case wrap() should set up a new input source to scan.
For example, continuing reading from std:cin after some other input source reached EOF:
To implement a wrap() (and yywrap() when option −−flex is specified) in a derived lexer class with option class=NAME (or yyclass=NAME), override the wrap() (or yywrap()) method as follows:
You can override the wrap() method to set up a new input source when the current input is exhausted. Do not use matcher().input(i) to set a new input source i, because that resets the internal matcher state.
With the −−flex options your can override the yyFlexLexer::yywrap() method that returns an integer 0 (more input available) or 1 (we're done).
With the −−flex and −−bison options you should define a global yywrap() function that returns an integer 0 (more input available) or 1 (we're done).
To set the current input as interactive, such as input from a console, use matcher().interactive() (yy_set_interactive(1) with option −−flex). This disables buffering of the input and makes the scanner responsive to direct input.
To read from the input without pattern matching, use matcher().input() to read one character at a time (8-bit, ASCII or UTF-8). This function returns EOF if the end of the input was reached. But be careful, the Flex yyinput() and input() functions return 0 instead of an EOF (-1)!
To put back one character unto the input stream, use matcher().unput(c) (or unput(c) with option −−flex) to put byte c back in the input or matcher().wunput(c) to put a (wide) character c back in the input.
unput() and wunput() invalidate the previous text() and yytext pointers. Basically, text() and yytext cannot be used after unput().For example, to crudily scan a C/C++ multiline comment we can use the rule:
We actually do not need to keep track of line numbers explicitly, because yyinput() with RE/flex implicitly updates line numbers, unlike Flex from which this example originates.
Instead of the crude approach shown above, a better alternative is to use a regex /\*.*?\*/ or perhaps use start condition states, see Start condition states .
A simpler and faster approach is to use skip("*/") to skip comments:
Using skip() is fast and flushes the internal buffer when searching, unlike yyinput() that maintains the buffer contents to keep text() (and yytext) unchanged.
To grab the rest of the input as a string, use matcher().rest() which returns a const char* string that points to the internal buffer that is enlarged to contain all remaining input. Copy the string before using the matcher again.
To read a number of bytes n into a string buffer s[0..n-1], use the virtual matcher().get(s, n) method. This method is the same as invoking matcher().in.get(s, n) to directly read data from the reflex::Input source in, but also handles interactive input when enabled with matcher().interactive() to not read beyond the next newline character. The gets, n) matcher method can be overriden by a derived matcher class to customize reading.
The Flex YY_INPUT macro is not supported by RE/flex. It is recommended to use YY_BUFFER_STATE (Flex), which is a reflex::FlexLexer::Matcher class in RE/flex that holds the matcher state and the state of the current input, including the line and column number positions (so unlike Flex, yylineno does not have to be saved and restored when switching buffers). See also section Lexer specifications on the actions to use.
To implement a custom input handler you can use a proper object-oriented approach: create a derived class of reflex::Matcher (or another matcher class derived from reflex::AbstractMatcher) and in the derived class override the size_t reflex::Matcher::get(char *s, size_t n) method for input handling. This function is called with a string buffer s of size n bytes. Fill the string buffer s up to n bytes and return the number of bytes stored in s. Return zero upon EOF. Use reflex options −−matcher=NAME and −−pattern=reflex::Pattern to use your new matcher class NAME (or leave out −−pattern for Boost.Regex derived matchers).
The FlexLexer lexer class is the base class of the yyFlexLexer lexer class generated with reflex option −−flex, which defines a virtual size_t LexerInput(char*, size_t) method. This virtual method can be redefined in the generated yyFlexLexer lexer to consume input from some source of text:
This approach is compatible with Flex. The LexerInput method may be invoked multiple times by the matcher engine and should eventually return zero to indicate the end of input is reached (e.g. when at EOF).
To prevent the scanner from initializing the input to stdin before reading input with LexerInput(), use option −−nostdinit.
A typical scenario for a compiler of a programming language is to process include directives in the source input that should include the source of another file before continuing with the current input.
For example, the following specification defines a lexer that processes #include directives by switching matchers and using the stack of matchers to permit nested #include directives up to a depth of as much as 99 files:
With option −−flex, the statement push_matcher(new_matcher(fd)) above becomes yypush_buffer_state(yy_create_buffer(fd, YY_BUF_SIZE)) and pop_matcher() becomes yypop_buffer_state(). For comparison, here is a C-based classic Flex example specification that works with RE/flex too:
Start conditions are used to group rules and selectively activate rules when the start condition state becomes active.
A rule with a pattern that is prefixed with one ore more start conditions will only be active when the scanner is in one of these start condition states.
For example:
When the scanner is in state A rules 1 and 2 are active. When the scanner is in state B rules 1 and 3 are active.
Start conditions are declared in The definitions section (the first section) of the lexer specification using %state or %xstate (or %s and %x for short) followed by a space-separated list of names called start symbols. Start conditions declared with %s are inclusive start conditions. Start conditions declared with %x are exclusive start conditions:
If a start condition is inclusive, then all rules without a start condition and rules with the corresponding start condition will be active.
If a start condition is exclusive, only the rules with the corresponding start condition will be active.
When declaring start symbol names it is recommended to use all upper case to avoid name clashes with other Lexer class members. For example, we cannot use text as a start symbol name because text() is a Lexer method. When option −−flex is specified, start symbol names are macros for compatibility with Lex/Flex.
The scanner is initially in the INITIAL start condition state. The INITIAL start condtion is inclusive: all rules without a start condition and those prefixed with the INITIAL start condition are active when the scanner is in the INITIAL start condition state.
The special start condition prefix <*> matches every start condition. The prefix <*> is not needed for <<EOF>> rules, because unprefixed <<EOF>> rules are always active as a special case. The <<EOF>> pattern and this exception were originally introduced by Flex.
For example:
When the scanner is in state INITIAL rules 4, 5, and 6 are active. When the scanner is in state A rules 1, 2, 4, 5, and 6 are active. When the scanner is in state X rules 1, 3, 4, and 6 are active. Note that A is inclusive whereas X is exclusive.
To switch to a start condition state, use start(START) (or BEGIN START when option −−flex is specified). To get the current state use start() (or YY_START when option −−flex is specified). Switching start condition states in your scanner allows you to create "mini-scanners" to scan portions of the input that are syntactically different from the rest of the input, such as comments:
Start symbols are actually integer values, where INITIAL is 0. This means that you can store a start symbol value in a variable. You can also push the current start condition on a stack and transition to start condition START with push_state(START). To transition to a start condition that is on the top of the stack and pop it use pop_state(). The top_state() returns the start condition that is on the top of the stack:
When many rules are prefixed by the same start conditions, you can simplify the rules by placing them in a start condition scope:
Start condition scopes may be nested. A nested scope extends the scope of start conditions that will be associated with the rules in the nested scope.
For example:
Designating a start condition as inclusive or exclusive is effective only for rules that are not associated with a start condition scope. That is, inclusive start condition states are implicitly associated with rules unless a rule has a start condition scope that explicitly associates start condition states with the rule.
RE/flex extends the syntax of start conditions scopes beyond Flex syntax, allowing the removal of start conditions from the current scope. A start condition name prefixed with the ^ operator is removed from the current scope:
Note that scopes should be read from outer to inner scope, and from left to right in a <...> scope declaration. This means that <*,^A,^C> first extends the scope to include all start conditions and then removes A and C.
A start condition cannot be removed when it is not included in the current scope. For example, <*,^A> is correct but <^A,*> is incorrect when used as a top-level scope.
Empty <> without start condition states cannot be specified because this is a valid regex pattern. To remove all states from a scope use <^*>. This construct is only useful when the empty scope is extended by start conditions specified in sub-scopes.
%option freespace allows patterns to be indented. With this option all action code blocks must be bracketed.An initial code block may be placed at the start of the rules section or in a condition scope. This code block is executed each time the scanner is invoked (i.e. when lex() or yylex() is called) before matching a pattern. Initial code blocks may be associated with start condition states as follows:
Initial code blocks should be indented or should be placed within %{ %} blocks.
An initial code block can be used to configure the lexer's matcher, since a new matcher with the lexer patterns is created by the lexer just before the rules are matched. For example:
The Bison tools generate parsers that invoke the global C function yylex() to get the next token. Tokens are integer values returned by yylex().
To support Bison parsers use reflex option −−bison. This option generates a scanner with a global lexer object YY_SCANNER and a global YY_EXTERN_C int yylex() function. When the Bison parser is compiled in C and the scanner is compiled in C++, you must set YY_EXTERN_C in the lex specification to extern "C" to enable C linkage rules:
Note that −−noyywrap may be specified to remove the dependency on the global yywrap() function that is not defined.
This example sets the global yylval.num to the integer scanned or yylval.str to the string scanned. It assumes that the Bison/Yacc grammar file defines the tokens CONST_NUMBER and CONST_STRING and the type YYSTYPE of yylval. For example:
YYSTYPE is a union defined by Bison or you can set it as an option %option YYSTYPE=type in a lexer specification.
When option −−flex is specified with −−bison, the yytext, yyleng, and yylineno globals are accessible to the Bison/Yacc parser. In fact, all Flex actions and variables are globally accessible (outside The rules section of the lexer specification) with the exception of yy_push_state, yy_pop_state, and yy_top_state that are class methods. Furthermore, yyin and yyout are macros and cannot be (re)declared or accessed as global variables, but these can be used as if they are variables to assign a new input source and to set the output stream. To avoid compilation errors when using globals such as yyin, use reflex option −−header-file to generate a header file lex.yy.h to include in your code. Finally, in code outside of The rules section you must use yyinput() instead of input(), use the global action yyunput() instead of unput(), and use the global action yyoutput() instead of output().
See the generated lex.yy.cpp "BISON" section, which contains declarations specific to Bison when the −−bison option is specified.
There are two approaches for a Bison parser to work with a scanner. Either the Bison/Yacc grammar file should include the externs we need to import from the scanner:
or a better approach is to generate a lex.yy.h header file with option −−header-file and use this header file in the Bison/Yacc grammar file:
The second option requires the generated parser to be compiled in C++, because lex.yy.h contains C++ declarations.
YY_DECL is not supported by RE/flex. The YY_DECL macro is used or defined by Flex to redeclare the yylex() function signature, See YY_DECL alternatives for more information.Bison and Yacc are not thread-safe because the generated code uses and updates global variables. Yacc and Bison use the global variable yylval to exchange token values. By contrast, thread-safe reentrant Bison parsers pass the yylval to the yylex() function as a parameter. RE/flex supports all of these Bison-specific features.
The following combinations of options are available to generate scanners for Bison:
| Options | Method | Global functions and variables |
|---|---|---|
int Lexer::lex() | no global variables, but doesn't work with Bison | |
−−flex | int yyFlexLexer::yylex() | no global variables, but doesn't work with Bison |
−−bison | int Lexer::lex() | Lexer YY_SCANNER, int yylex(), YYSTYPE yylval |
−−flex −−bison | int yyFlexLexer::yylex() | yyFlexLexer YY_SCANNER, int yylex(), YYSTYPE yylval, char *yytext, yy_size_t yyleng, int yylineno |
−−bison −−reentrant | int Lexer::lex() | int yylex(yyscan_t), void yylex_init(yyscan_t*), void yylex_destroy(yyscan_t) |
−−flex −−bison −−reentrant | int yyFlexLexer::lex() | int yylex(yyscan_t), void yylex_init(yyscan_t*), void yylex_destroy(yyscan_t) |
−−bison-locations | int Lexer::lex(YYSTYPE& yylval) | Lexer YY_SCANNER, int yylex(YYSTYPE *yylval, YYLTYPE *yylloc) |
−−flex −−bison-locations | int yyFlexLexer::yylex(YYSTYPE& yylval) | yyFlexLexer YY_SCANNER, int yylex(YYSTYPE *yylval, YYLTYPE *yylloc) |
−−bison-bridge | int Lexer::lex(YYSTYPE& yylval) | int yylex(YYSTYPE *yylval, yyscan_t), void yylex_init(yyscan_t*), void yylex_destroy(yyscan_t) |
−−flex −−bison-bridge | int yyFlexLexer::yylex(YYSTYPE& yylval) | int yylex(YYSTYPE *yylval, yyscan_t), void yylex_init(yyscan_t*), void yylex_destroy(yyscan_t) |
−−bison-bridge −−bison-locations | int Lexer::lex(YYSTYPE& yylval) | int yylex(YYSTYPE *yylval, YYLTYPE *yylloc, yyscan_t), void yylex_init(yyscan_t*), void yylex_destroy(yyscan_t) |
−−flex −−bison-bridge −−bison-locations | int yyFlexLexer::yylex(YYSTYPE& yylval) | int yylex(YYSTYPE *yylval, YYLTYPE *yylloc, yyscan_t), void yylex_init(yyscan_t*), void yylex_destroy(yyscan_t) |
−−bison-cc | int Lexer::yylex(YYSTYPE *yylval) | no global variables |
−−flex −−bison-cc | int yyFlexLexer::yylex(YYSTYPE *yylval) | no global variables |
−−bison-cc −−bison-locations | int Lexer::yylex(YYSTYPE *yylval, YYLTYPE *yylloc) | no global variables |
−−flex −−bison-cc −−bison-locations | int yyFlexLexer::yylex(YYSTYPE *yylval, YYLTYPE *yylloc) | no global variables |
−−bison-complete | PARSER::symbol_type Lexer::yylex() | no global variables |
−−flex −−bison-complete | PARSER::symbol_type yyFlexLexer::yylex() | no global variables |
−−bison-complete −−bison-locations | PARSER::symbol_type Lexer::yylex() | no global variables |
−−flex −−bison-complete −−bison-locations | PARSER::symbol_type yyFlexLexer::yylex() | no global variables |
Option −−prefix may be used with option −−flex to change the prefix of the generated yyFlexLexer and yylex. This option may be combined with option −−bison to also change the prefix of the generated yytext, yyleng, and yylineno.
Furthermore, reflex options −−namespace=NAME, −−lexer=LEXER and −−lex=LEX can be used to add a C++ namespace, to rename the lexer class (Lexer or yyFlexLexer by default) and to rename the lexer function (lex or yylex by default), respectively.
For option −−bison-complete the lexer function return type is the parser's symbol_type as defined in the Bison grammar specification. The parser class is specified with option −−bison-cc-parser=PARSER and an optional namespace may be specified with −−bison-cc-namespace=NAME. The lexer function return type may also be explicitly specified with option −−token-type=TYPE.
The following sections explain the −−bison-cc, −−bison-complete, −−bison-bridge, −−bison-locations, and −−reentrant options for reflex.
Additional parameters may be passed to lex() and yylex() by declaring %option params="extra parameters" in the lexer specification. See YY_DECL alternatives.
The reflex option −−bison-cc expects a Bison 3.0 %skeleton "lalr1.cc" C++ parser that is declared as follows in a Bison grammar file:
With the −−bison-cc option of reflex, the yylex() function takes a yy::parser::semantic_type yylval argument that makes the yylval visible in the lexer rules to assign semantic values to.
The scanner is generated with reflex options −−bison-cc, −−namespace=yy and −−lexer=Lexer. The lexer specification should #include the Bison-generated header file to ensure that the yy::parser::token enums CONST_NUMBER and CONST_STRING are defined.
Using the code above, we can now initialize a Bison parser. We first should create a scanner and pass it to the parser constructor as follows:
We use options −−bison-cc-namespace=NAME and −−bison-cc-parser=NAME to specify the namespace and parser class name of the Bison 3.0 %skeleton "lalr1.cc" C++ parser you are generating with Bison. These are yy and parser by default, respectively. For option −−bison-cc-namespace=NAME the NAME can be a list of nested namespaces of the form NAME1::NAME2::NAME3 or by separating the names by a dot as in NAME1.NAME2.NAME3.
The reflex option −−bison-cc with −−bison-locations expects a Bison 3.0 %skeleton "lalr1.cc" C++ parser that is declared as follows in a Bison grammar file:
With the −−bison-cc and −−bison-locations options of reflex, the yylex() function takes yy::parser::semantic_type yylval as the first argument that makes the yylval visible in the lexer rules to assign semantic values to. The second argument yy::location yylloc is set automatically by by invoking the lexer's yylloc_update() in yylex() to update the line and column of the match. The auto-generated virtual yylloc_update() method can be overriden by a user-defined lexer class that extends Lexer (or extends yyFlexLexer when option −−flex is specified).
The scanner is generated with reflex options −−bison-cc, −−bison-locations, −−namespace=yy and −−lexer=Lexer. The lexer specification should #include the Bison-generated header file to ensure that the yy::parser::token enums CONST_NUMBER and CONST_STRING are defined.
Using the code above, we can now initialize a Bison parser. We first should create a scanner and pass it to the parser constructor as follows:
The reflex option −−bison-complete expects a Bison 3.2 C++ parser which uses both %define api.value.type variant and %define api.token.constructor. This parser defines the type symbol_type variant and the parser expects yylex to have the type yy::parser::symbol_type yylex(). Here is an example Bison 3.2 C++ complete symbols grammar file:
With the −−bison-complete option of reflex, the yylex() function takes no arguments by default and returns a value of type yy::parser::symbol_type. This means that the lexer's action should return values of this type, constructed with yy::parser::symbol_type or with make_TOKENNAME as follows:
The scanner is generated with reflex options −−bison-complete, −−namespace=yy and −−lexer=Lexer. Option −−bison-complete automatically defines the appropriate token type symbol_type depending on −−bison-cc-namespace and on −−bison-cc-parser. We also used options −−bison-cc-namespace=NAME and −−bison-cc-parser=NAME to specify the namespace and parser class name of the Bison 3.2 C++ parser. These are yy and parser by default, respectively (%define api.namespace {yy} and %define api.parser.class {parser} are actually superfluous in the example grammer specification because their values are the defaults). We use option −−exception to specify that the scanner's default rule should throw a yy::parser::syntax_error("Unknown token."). This exception is caught by the parser which calls yy::parser::error with the string "Unknown token." as argument.
We have to be careful with option −−exception. Because no input is consumed, the scanner should not be invoked again or we risk looping on the unmatched input. Alternatively, we can define a "catch all else" rule with pattern . that consumes the offending input:
For option −−bison-cc-namespace=NAME the NAME may be a list of nested namespaces of the form NAME1::NAME2::NAME3 or by separating the names by a dot as in NAME1.NAME2.NAME3.
Using the code above, we can now initialize a Bison parser in our main program. We first should create a scanner and pass it to the parser constructor as follows:
Note that when the end of input is reached, the lexer returns yy::parser::make_EOF() upon matching <<EOF>>. This rule is optional. When omitted, the return value is yy::parser::symbol_type(0).
The reflex option −−bison-complete expects a Bison 3.2 C++ parser which uses both %define api.value.type variant and %define api.token.constructor. This parser defines the type symbol_type variant and the parser expects yylex to have the type parser::symbol_type::yylex(). Here is an example Bison 3.2 C++ complete symbols grammar file with Bison %locations enabled:
With the −−bison-complete option of reflex, the yylex() function takes no arguments by default and returns a value of type yy::parser::symbol_type. This means that the lexer's action should return values of this type, constructed with yy::parser::symbol_type or with make_TOKENNAME as follows:
The scanner is generated with reflex options −−bison-complete, −−bison-locations, −−namespace=yy and −−lexer=Lexer. Option −−bison-complete automatically defines the appropriate token type symbol_type depending on −−bison-cc-namespace and on −−bison-cc-parser. We also used options −−bison-cc-namespace=NAME and −−bison-cc-parser=NAME to specify the namespace and parser class name of the Bison 3.2 C++ parser. These are yy and parser by default, respectively (i.e. define api.namespace {yy} and define api.parser.class {parser} are actually superfluous in the example grammer specification because their values are the defaults). We use option −−exception to specify that the scanner's default rule should throw a yy::parser::syntax_error(location(), "Unknown token."). This exception is caught by the parser which calls yy::parser::error with the value of location() and the string "Unknown token." as arguments. The auto-generated virtual lexer class method location() method may be overriden by a user-defined lexer class that extends Lexer (or extends yyFlexLexer when option −−flex is specified).
We have to be careful with option −−exception. Because no input is consumed, the scanner should not be invoked again or we risk looping on the unmatched input. Alternatively, we can define a "catch all else" rule with pattern . that consumes the offending input:
For option −−bison-cc-namespace=NAME the NAME may be a list of nested namespaces of the form NAME1::NAME2::NAME3 or by separating the names by a dot as in NAME1.NAME2.NAME3.
Using the code above, we can now initialize a Bison parser in our main program. We first should create a scanner and pass it to the parser constructor as follows:
Note that when the end of input is reached, the lexer returns yy::parser::make_EOF() upon matching <<EOF>>. This rule is optional. When omitted, the return value is yy::parser::symbol_type(0, location()).
The reflex option −−bison-bridge expects a Bison "pure parser" that is declared as follows in a Bison grammar file:
%pure-parser is deprecated and replaced with %define api.pure.With the −−bison-bridge option of reflex, the yyscan_t argument type of yylex() is a void* type that passes the scanner object to this global function (as defined by YYPARSE_PARAM and YYLEX_PARAM). The function then invokes this scanner's lex function. This option also passes the yylval value to the lex function, which is a reference to an YYSTYPE value.
Wtih the −−bison-bridge option two additional functions are generated that should be used to create a new scanner and delete the scanner in your program:
The option −−bison-locations expects a Bison parser with the locations feature enabled. This feature provides line and column numbers of the matched text for error reporting. For example:
The yylval value is passed to the lex function. The yylloc structure is automatically updated by the RE/flex scanner, so you do not need to define a YY_USER_ACTION macro as you have to with Flex. Instead, this is done automatically in yylex() by invoking the lexer's yylloc_update() to update the line and column of the match. The auto-generated virtual yylloc_update() method may be overriden by a user-defined lexer class that extends Lexer (or extends yyFlexLexer when option −−flex is specified).
Note that with the −−bison-location option, yylex() takes an additional YYLTYPE argument that a Bison parser provides. You can set YYLTYPE as an option %option YYLTYPE=type in a lexer specification.
Here is a final example that combines options −−bison-locations and −−bison-bridge, The Bison parser should be a Bison pure-parser with locations enabled:
%pure-parser is deprecated and replaced with %define api.pure.%locations with %define api.pure full is used, yyerror has the signature void yyerror(YYLTYPE *locp, char const *msg). This function signature is required to obtain the location information with Bison pure-parsers.yylval is not a pointer but is passed by reference and should be used as such in the scanner's rules.YYSTYPE is declared by the parser, do not forget to add a #include "y.tab.h" to the top of the specification of your lexer:With the −−bison-bridge and −−bison-location options two additional functions are generated that should be used to create a new scanner and delete the scanner in your program:
Option -R or −−reentrant may be used to generate a reentrant scanner that is compatible with reentrant Flex and Bison. This is mainly useful when you combine −−reentrant with −−flex and −−bison. See also Interfacing with Bison/Yacc .
When using Bison with reentrant scanners, your code should create a yyscan_t scanner object with yylex_init(&scanner) and destroy it with yylex_destroy(scanner). Reentrant Flex functions take the scanner object as an extra last argument, for example yylex(scanner):
Within a rules section we refer to the scanner with macro yyscanner, for example:
The following functions are available in a reentrant Flex scanner generated with options −−flex and −−reentrant. These functions take an extra argument yyscan_t s that is either yyscanner when the function is used in a rule or in the scope of a lexer method, or is a pointer to the lexer object when the function is used outside the scope of a lexer method:
| Reentrant Flex action | Result |
|---|---|
yyget_text(s) | 0-terminated text match |
yyget_leng(s) | size of the match in bytes |
yyget_lineno(s) | line number of the match (>=1) |
yyset_lineno(n, s) | set line number of the match to n |
yyset_columno(n, s) | set column number of the match to n |
yyget_in(s) | get reflex::Input object |
yyset_in(i, s) | set reflex::Input object |
yyget_out(s) | get std::ostream object |
yyset_out(o, s) | set output to std::ostream o |
yyget_debug(s) | reflex option -d sets n=1 |
yyset_debug(n, s) | reflex option -d sets n=1 |
yyget_extra(s) | get user-defined extra parameter |
yyset_extra(x, s) | set user-defined extra parameter |
yyget_current_buffer(s) | the current matcher |
yyrestart(i, s) | set input to reflex::Input i |
yyinput(s) | get next 8-bit char from input |
yyunput(c, s) | put back 8-bit char c |
yyoutput(c, s) | output char c |
yy_create_buffer(i, n, s) | new matcher reflex::Input i |
yy_delete_buffer(m, s) | delete matcher m |
yypush_buffer_state(m, s) | push current matcher, use m |
yypop_buffer_state(s) | pop matcher and delete current |
yy_scan_string(s) | scan string s |
yy_scan_wstring(s) | scan wide string s |
yy_scan_bytes(b, n) | scan n bytes at b (buffered) |
yy_scan_buffer(b, n) | scan n-1 bytes at b (zero copy) |
yy_push_state(n, s) | push current state, go to state n |
yy_pop_state(s) | pop state and make it current |
yy_top_state(s) | get top state start condition |
With respect to the yyget_extra functions, a scanner object has a YY_EXTRA_TYPE yyextra value that is user-definable. You can define the type in a lexer specification with the extra-type option:
This mechanism is somewhat crude as it originates with Flex' C legacy to add extra user-defined values to a scanner class. Because reflex is C++, it is recommended to define a derived class that extends the Lexer or FlexLexer class, see Inheriting Lexer/yyFlexLexer .
Because scanners are C++ classes, the yyscanner macro is essentially the same is the this pointer. Outside the scope of lexer methods a pointer to your yyFlexLexer lexer object should be used instead.
The Flex macro YY_DECL is not supported by RE/flex. The YY_DECL macro is typically used with FLex to (re)declare the yylex() function signature, for example to take an additional yylval parameter that must be passed through from yyparse() to yylex(). Note that the standard cases are already covered by RE/flex using options such as −−bison-cc, −−bison-bridge and −−bison-locations that pass additional parameters to the scanner function invoked by the Bison parser.
There are two better alternatives to YY_DECL:
%option params="TYPE NAME, ..." can be defined in the lexer specification to pass additional parameters to the lexer function lex() and yylex(). One or more corresponding Bison %param declarations should be included in the grammar specification, to pass the extra parameters via yyparse() to lex()/yylex(). Also yyerror() is expected to take the extra parameters.%class{ } can be extended with member declarations to hold state information, such as token-related values. These values can then be exchanged with the parser by accessing them within the parser.The first alternative matches the YY_DECL use cases. The comma-separated list of additional parameters "TYPE NAME, ..." are added to the end of the parameter list of the generated lex()/yylex() function. The second alternative uses a stateful approach. The values are stored in the scanner object and can be made accessible beyond the scopes of the scanners's rule actions and the parser's semantic actions.
See also The Lexer/yyFlexLexer class .
RE/flex generates an efficient search engine with option -S (or −−find). The generated search engine finds all matches while ignoring unmatched input silently, which is different from scanning that matches all input piece-wise.
Searching with this option is more efficient than scanning with a "catch all else" dot-rule to ignore unmatched input, as in:
The problem with this rule is that it is invoked for every single unmatched character in the input, which is inefficient and slows down searching significantly when more than a few unmatched characters are encountered in the input. Note that we cannot use .+ to match longer patterns because this overlaps with other patterns and is also likely longer than the other patterns, i.e. the rule subsumes all other patterns.
Option -S (or −−find) speeds up searching significantly. Hashed bitap combined with hashed predict-match and SIMD acceleration are used.
This option only applies to the RE/flex matcher and can be combined with options -f (or −−full) and -F (or −−fast) to further increase performance. With one of these options, a FSM in C++ code or an opcode table is saved together with a pattern predictor table that is used to accelerate search.
-S (or −−find), a "catch all else" dot-rule should not be defined, since unmatched input is already ignored with this option and defining a "catch all else" dot-rule actually slows down the search.-s (or −−nodefault) cannot be used to ignore unmatched input. Option -s produces runtime errors and exceptions for unmatched input.The reflex scanner generator gives you a choice of matchers to use in the generated scanner, where the default is the POSIX RE/flex matcher engine. Other options are the Boost.Regex matcher in POSIX mode or in Perl mode.
To use a matcher for the generated scanner, use one of these three choices:
| Option | Matcher class used | Mode | Engine |
|---|---|---|---|
-m reflex | Matcher | POSIX | RE/flex lib (default choice) |
-m pcre2-perl | PCRE2Matcher | Perl | PCRE2 |
-m boost | BoostPosixMatcher | POSIX | Boost.Regex |
-m boost-perl | BoostPerlMatcher | Perl | Boost.Regex |
The POSIX matchers look for the longest possible match among the given set of alternative patterns. Perl matchers look for the first match among the given set of alternative patterns.
POSIX is generally preferred for scanners, since it is easier to arrange rules that may have partially overlapping patterns. Since we are looking for the longest match anyway, it does not matter which rule comes first. The order does not matter as long as the length of the matches differ. When matches are of the same length because multiple patterns match, then the first rule is selected.
Consider for example the following lexer.l specification if a lexer with rules that are intended to match keywords and identifiers in some input text:
When the input to the scanner is the text integer, a POSIX matcher selects the last rule that matches it by leftmost longest matching policy. This matching policy selects the rule that matches the longest text. If more than one pattern matches the same length of text then the first pattern that matches takes precedence. This is what we want because it is an identifier in our example programming language:
reflex -m reflex −−main lexer.l c++ -o lexer lex.yy.cpp -lreflex echo "integer" | ./lexer => identifier
By contrast, a Perl matcher uses a greedy matching policy, which selects the first rule that matches. In this case it matches the first part int of the text integer and leaves erface to be matched next as an identifier:
reflex -m boost-perl −−main lexer.l c++ -o lexer lex.yy.cpp -lreflex -lboost_regex echo "integer" | ./lexer => int keyword => identifier
Note that the same greedy matching happens when the text interface is encountered on the input, which we want to recognize as a separate keyword and not match against int:
reflex -m boost-perl −−main lexer.l c++ -o lexer lex.yy.cpp -lreflex -lboost_regex echo "interface" | ./lexer => int keyword => identifier
Switching the rules for int and interface fixes that specific problem.
reflex -m boost-perl −−main lexer.l c++ -o lexer lex.yy.cpp -lreflex -lboost_regex echo "interface" | ./lexer => interface keyword
But we cannot do the same to fix matching integer as an identifier: when moving the last rule up to the top we cannot match int and interface any longer!
reflex -m boost-perl −−main lexer.l c++ -o lexer lex.yy.cpp -lreflex -lboost_regex echo "int" | ./lexer => identifier echo "interface" | ./lexer => identifier
Basically, a Perl matcher works in an operational mode by working the regex pattern as a sequence of operations for matching, usually using backtracking to find a matching pattern.
Perl matching differs from POSIX matching in that regex patterns are matched from the first to the last specified, with the first pattern match winning. This means that rule order is important, even more than POSIX matching. By contrast, POSIX matches the longest pattern and ambiguity only exists when two regex patterns match the same input. The RE/flex scanner generator warns about POSIX regex pattern rules ambiguities, but does not do so for overlapping Perl regex pattern rules.
To prevent a Perl matcher from matching a keyword when an identifier starts with the name of that keyword, we could use a lookahead pattern such as int(?=[^A-Za-z0-9_]) which is written in a lexer specification with a trailing context int/[^A-Za-z0-9_] with the / lookahead meta symbol.
A POSIX matcher on the other hand is declarative with a deeper foundation in formal language theory. An advantage of POSIX matchers is that a regular expression can always be compiled to a deterministic finite state machine for efficient matching.
POSIX matching still requires the int matching rule before the identifier matching rule, as in the original lexer specification shown in this section. Otherwise an int on the input will be matched by the identifier rule.
Perl matchers generally support lazy quantifiers and group captures, while most POSIX matchers do not (e.g. Boost.Regex in POSIX mode does not support lazy quantifiers). The RE/flex POSIX matcher supports lazy quantifiers, but not group captures. The added support for lazy quantifiers and word boundary anchors in RE/flex matching offers a reasonably new and useful feature for scanners that require POSIX mode matching.
For example, with the default RE/flex POSIX matcher (or with a Perl matcher) we can ignore single and multiline C/C++ comments using lazy repetitions:
Likewise, this example ignores XML comments:
An example to match and scan quoted strings:
If we permit strings to contain escaped quotes, then this example scans those:
We can also scan nestings, such as foo(bar(baz())), as one token stored in yytext using a single rule in a separate start condition state NESTINGS (to isolate this agressive scanning from the other rules):
Lookaheads can also be used with Perl and POSIX matchers to prioratize rules. Adding a lookahead lengthens the pattern while keeping only the part that matches before the lookahead. For example, the following lexer specification attempts to remove leading 0 from numbers:
However, in POSIX mode the first rule only matches if the text is exactly one 0 because the second rule matches longer texts. The trick here is to use a trailing context with the first rule as follows:
reflex -m reflex −−main lexer.l c++ -o lexer lex.yy.cpp -lreflex echo "00123" | ./lexer => 123 echo "0" | ./lexer => 0
There are several reflex options to debug a lexer and analyze its performance given some input text to scan:
-d (or −−debug) generates a scanner that prints the matched text, which allows you to debug your lexer patterns.-D [START:]FILE (or −−do=[START:]FILE) does not generate a scanner, but immediately prints the matched text by matching the lexer patterns against the specified input FILE. This option allows you to debug your patterns immediately. An optional START condition state of the rules may be specified, which is 0 (or INITIAL) by default.-p (or −−perf-report) generates a scanner that profiles the performance of your lexer and the lexer rules executed, which allows you to find hotspots and performance bottlenecks in your lexer.-s (or −−nodefault) suppresses the default rule that echoes all unmatched text when no rule matches. The scanner reports "scanner jammed" when no rule matches. Without the −−flex option, a std::runtime exception is thrown.-v (or −−verbose) displays a summary of scanner statistics.Option -d generates a scanner that prints the matched text while scanning input. The output displayed is of the form:
−−rule FILE:LINE start(START) LINE,COLUMN:"TEXT"
where FILE:LINE is the source location of the lexer rule, START is the start condition state, LINE,COLUMN is the line and column number of the pattern match in the input, and TEXT is the matched text.
Option -D [START:]FILE immediately debugs the lexer patterns on the specified input FILE. The start condition state START is not changed during scanning, because the scanner's lexer actions are not actually executed.
Option -p generates a scanner that profiles the performance of your lexer. The performance report shows the performance statistics obtained for each pattern defined in the lexer specification, i.e. the number of matches per pattern, the total text length of the matches per pattern, and the total time spent matching and executing the rule corresponding to the pattern. The performance profile statistics are collected when the scanner runs on some given input. Profiling allows you to effectively fine-tune the performance of your lexer by focussing on patterns and rules that are frequently matched that turn out to be computationally expensive.
This is perhaps best illustrated with an example. The JSON parser json.l located in the examples directory of the RE/flex download package was built with reflex option -p and then run on some given JSON input to analyze its performance:
reflex x.y.z json.l performance report:
INITIAL rules matched:
rule at line 51 accepted 58 times matching 255 bytes total in 0.009 ms
rule at line 52 accepted 58 times matching 58 bytes total in 0.824 ms
rule at line 53 accepted 0 times matching 0 bytes total in 0 ms
rule at line 54 accepted 0 times matching 0 bytes total in 0 ms
rule at line 55 accepted 0 times matching 0 bytes total in 0 ms
rule at line 56 accepted 5 times matching 23 bytes total in 0.007 ms
rule at line 57 accepted 38 times matching 38 bytes total in 0.006 ms
rule at line 72 accepted 0 times matching 0 bytes total in 0 ms
default rule accepted 0 times
STRING rules matched:
rule at line 60 accepted 38 times matching 38 bytes total in 0.021 ms
rule at line 61 accepted 0 times matching 0 bytes total in 0 ms
rule at line 62 accepted 0 times matching 0 bytes total in 0 ms
rule at line 63 accepted 0 times matching 0 bytes total in 0 ms
rule at line 64 accepted 0 times matching 0 bytes total in 0 ms
rule at line 65 accepted 0 times matching 0 bytes total in 0 ms
rule at line 66 accepted 0 times matching 0 bytes total in 0 ms
rule at line 67 accepted 0 times matching 0 bytes total in 0 ms
rule at line 68 accepted 314 times matching 314 bytes total in 0.04 ms
rule at line 69 accepted 8 times matching 25 bytes total in 0.006 ms
rule at line 72 accepted 0 times matching 0 bytes total in 0 ms
default rule accepted 0 times
WARNING: execution times are relative:
1) includes caller's execution time between matches when yylex() returns
2) perf-report instrumentation adds overhead and increases execution times
The timings shown include the time of the pattern match and the time of the code executed by the rule. If the rule returns to the caller than the time spent by the caller is also included in this timing. For this example, we have two start condition states namely INITIAL and STRING. The rule at line 52 is:
This returns a [ or ] bracket, a { or } brace, a comma, or a colon to the parser. Since the pattern and rule are very simple, we do not expect these to contribute much to the 0.824 ms time spent on this rule. The parser code executed when the scanner returns could be expensive. Depending on the character returned, the parser constructs a JSON array (bracket) or a JSON object (brace), and populates arrays and objects with an item each time a comma is matched. But which is most expensive? To obtain timings of these events separately, we can split the rule up into three similar rules:
Then we use reflex option -p, recompile the generated scanner lex.yy.cpp and rerun our experiment to see these changes:
rule at line 52 accepted 2 times matching 2 bytes total in 0.001 ms
rule at line 53 accepted 14 times matching 14 bytes total in 0.798 ms
rule at line 54 accepted 42 times matching 42 bytes total in 0.011 ms
So it turns out that the construction of a JSON object by the parser is relatively speaking the most expensive part of our application, when { and } are encountered on the input. We should focus our optimization effort there if we want to improve the overall speed of our JSON parser.
Some lexer specification examples to generate scanners with RE/flex.
The following Flex specification counts the lines, words, and characters on the input. We use yyleng match text length to count 8-bit characters (bytes).
To build this example with RE/flex, use reflex option −−flex to generate Flex-compatible "yy" variables and functions. This generates a C++ scanner class yyFlexLexer that is compatible with the Flex scanner class (assuming Flex with option -+ for C++).
To generate a scanner with a global yylex() function similar to Flex in C mode (i.e. without Flex option -+), use reflex option −−bison with the specification shown above. This option when combined with −−flex produces the global "yy" functions and variables. This means that you can use RE/flex scanners with Bison (Yacc) and with any other C code, assuming everything is compiled together with a C++ compiler.
An improved implementation drops the use of global variables in favor of Lexer class member variables. We also want to count Unicode letters with the wd counter instead of ASCII letters, which are single bytes while Unicode UTF-8 encodings vary in size. So we add the Unicode option and use \w to match Unicode word characters. Note that . (dot) matches Unicode, so the match length may be longer than one character that must be counted. We drop the −−flex option and use RE/flex Lexer methods instead of the Flex "yy" functions:
This simple word count program differs slightly from the Unix wc utility, because the wc utility counts words delimited by wide character spaces (iswspace) whereas this program counts words made up from word characters combined with punctuation.
The following RE/flex specification filters tags from XML documents and verifies whether or not the tags are properly balanced. Note that this example uses the lazy repetitions to keep the patterns simple. The XML document scanned should not include invalid XML characters such as /, <, or > in attributes (otherwise the tags will not match properly). The dotall option allows . (dot) to match newline in all patterns, similar to the (?s) modifier in regexes.
Note thay we restrict XML tag names to valid characters, including all UTF-8 sequences that run in the range \x80-\xFF per 8-bit character. This matches all Unicode characters U+0080 to U+10FFFF.
The ATTRIBUTES state is used to scan attributes and their quoted values separately from the INITIAL state. The INITIAL state permits quotes to freely occur in character data, whereas the ATTRIBUTES state matches quoted attribute values.
We use matcher().less(size() - 1) to remove the ending > from the match in text(). The > will be matched again, this time by the <*>. rule that ignores it. We could also have used a lookahead pattern "\</"{name}/"\>" where X/Y means look ahead for Y after X.
This example Flex specification scans non-Unicode C/C++ source code. It uses free space mode to enhance readability.
Free space mode permits spacing between concatenations and alternations. To match a single space, use " " or [ ]. Long patterns can continue on the next line(s) when lines ends with an escape \.
In free space mode you MUST place actions in { } blocks and user code in %{ %} blocks instead of indented.
When used with option unicode, the scanner automatically recognizes and scans Unicode identifier names. Note that we can use matcher().columno() or matcher().border() in the error message to indicate the location on a line of the match. The matcher().columno() method takes tab spacing and wide characters into account. To obtain the byte offset from the start of the line use matcher().border(). The matcher() object associated with the Lexer offers several other methods that Flex does not support.
This example defines a search engine to find C/C++ directives, such as #define and #include, in the input fast.
Option %o find (-S or −−find) specifies that unmatched input text should be ignored silently instead of being echoed to standard output, see Searching versus scanning . Option %fast (-F or −−fast) generates an efficient FSM in direct code.
The RE/flex matcher engine uses an efficient FSM. There are known limitations to FSM matching that apply to Flex/Lex and therefore also apply to the reflex scanner generator and to the RE/flex matcher engine:
a/b (which is the same as lookahead a(?=b)) is permitted, but (a/b)c and a(?=b)c are not.zx*/xy*, where the x* matches the x at the beginning of the lookahead pattern. This is a common limitation that also Lex and Flex (with some ad-hoc exceptions) have.REJECT action is not supported.p, n, a, e, k, and o are not supported; o may also be used as a shorthand for option.%T are not supported.\<, \>, \b and \B are supported by RE/flex using backtracking (since RE/flex version 3.4.1). Except that option −−fast does not produce code that backtracks, which means that patterns such as bar.*\bfoo that require backtracking on \b may not work properly. If necessary, use option −−full when word boundaries are used when these require backtracking to find a match.Some of these limitations may be removed in future versions of RE/flex.
Boost.Regex library limitations:
φ(?<=ψ) with the Boost.Regex matcher engines should not look too far behind. Any input before the current line may be discarded and is no longer available when new input is shifted into the internal buffer. Only input on the current line from the start of the line to the match is guaranteed..* are used. Under certain conditions greedy repetitions may behave as lazy repetitions. For example, the Boost.Regex engine may return the short match abc when the regex a.*c is applied to abc abc, instead of returning the full match abc abc. The problem is caused by the limitations of Boost.Regex match_partial matching algorithm. To work around this limitation, we suggest to make the repetition pattern as specific as possible and not overlap with the pattern that follows the repetition. The easiest solution is to read the entire input using reflex option -B (batch input). For a stand-alone BoostMatcher, use the buffer() method. We consider this Boost.Regex partial match behavior a bug, not a restriction, because as long as backtracking on a repetition pattern is possible given some partial text, Boost.Regex should flag the result as a partial match instead of a full match.PCRE2 library limitations:
φ(?<=ψ) with the PCRE2 matcher engines should not look too far behind. Any input before the current line may be discarded and is no longer available when new input is shifted into the internal buffer. Only input on the current line from the start of the line to the match is guaranteed.The RE/flex regex library consists of a set of C++ templates and classes that encapsulate regex engines in a standard API for scanning, tokenizing, searching, and splitting of strings, wide strings, files, and streams.
The RE/flex regex library is a class hierarchy that has at the root an abstract class reflex::AbstractMatcher. Pattern types may differ between for matchers so the reflex::PatternMatcher template class takes a pattern type and creates a class that is complete except for the implementation of the reflex::match() virtual method that requires a regex engine, such as PCRE2, Boost.Regex, or the RE/flex engine.
To compile your application, simply include the applicable regex matcher of your choice in your source code as we will explain in the next sections. To compile, link your application against the libreflex library:
c++ myapp.cpp -lreflex
And optionally -lpcre2-8 if you want to use PCRE2 for searching and matching:
c++ myapp.cpp -lreflex -lpcre2-8
or -lboost_regex if you want to use Boost.Regex for searching and matching:
c++ myapp.cpp -lreflex -lboost_regex
If libreflex was not installed then linking with -lreflex fails. See Undefined symbols and link errors on how to resolve this.
The reflex::PCRE2Matcher inherits reflex::PatternMatcher<std::string>. The reflex::PCRE2UTFMatcher is derived from reflex::PCRE2Matcher:
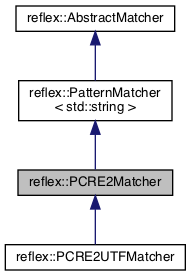
An instance of reflex::PCRE2Matcher is initialized with a pattern that is compiled with pcre2_compile() and pcre2_jit_compile() for optimal performance with PCRE2 JIT-generated code.
An instance of reflex::PCRE2UTFMatcher creates a PCRE2 matcher with native Unicode support, using PCRE2 options PCRE2_UTF+PCRE2_UCP.
PCRE2 is a powerful library. The RE/flex regex API enhances this library with operations to match, search, scan, and split data from a given input. The input may be a file, a string, or a stream. Files that are UTF-8/16/32-encoded are automatically decoded. Further, streams can be of potentially unlimited length because internal buffering is used by the RE/flex regex API enhancements to efficiently apply PCRE2 partial pattern matching to streaming data. This enhancement permits pattern matching of interactive input from the console, such that searching and scanning interactive input for matches will return these matches immediately.
A reflex::PCRE2Matcher (or reflex::PCRE2UTFMatcher) engine is created from a string regex and some given input:
Likewise, a reflex::PCRE2UTFMatcher engine is created from a string regex and some given input:
This matcher uses PCRE2 native Unicode matching. Non-UTF input is not supported, such as plain binary. UTF encoding errors in the input will cause the matcher to terminate.
For input you can specify a string, a wide string, a file, or a stream object.
We use option "N" to permit empty matches when searching input with reflex::PCRE2Matcher::find.
You can convert an expressive regex of the form defined in Patterns to a regex that the PCRE2 engine can handle:
The converter is specific to the matcher selected, i.e. reflex::PCRE2Matcher::convert and reflex::PCRE2UTFMatcher::convert. The former converter converts Unicode \p character classes to UTF-8 patterns, converts bracket character classes containing Unicode, and groups UTF-8 multi-byte sequences in the regex string. The latter converter does not convert these regex constructs, which are matched by the PCRE2 engine initialized with options PCRE2_UTF+PCRE2_UCP.
The converter throws a reflex::regex_error exception if conversion fails, for example when the regex syntax is invalid.
To compile your application, link your application against the libreflex library and -lpcre2-8:
c++ myapp.cpp -lreflex -lpcre2-8
See Patterns for more details on regex patterns.
See The Input class for more details on the reflex::Input class.
See Methods and iterators for more details on pattern matching methods.
See Regex converters for more details on regex converters.
The reflex::BoostMatcher inherits reflex::PatternMatcher<boost::regex>, and in turn the reflex::BoostPerlMatcher and reflex::BoostPosixMatcher are both derived from reflex::BoostMatcher:
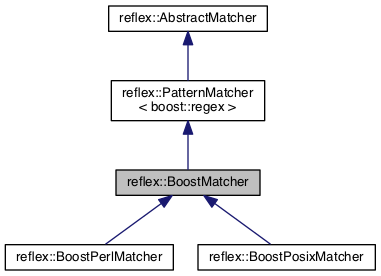
An instance of reflex::BoostPerlMatcher is initialized with flag match_perl and the flag match_not_dot_newline, these are boost::regex_constants flags. These flags are the only difference with the plain reflex::BoostMatcher.
An instance of reflex::BoostPosixMatcher creates a POSIX matcher. This means that lazy quantifiers are not supported and the leftmost longest rule applies to pattern matching. This instance is initialized with the flags match_posix and match_not_dot_newline.
Boost.Regex is a powerful library. The RE/flex regex API enhances this library with operations to match, search, scan, and split data from a given input. The input may be a file, a string, or a stream. Files that are UTF-8/16/32-encoded are automatically decoded. Further, streams can be potentially of unlimited length because internal buffering is used by the RE/flex regex API enhancements to efficiently apply Boost.Regex partial pattern matching to streaming data. This enhancement permits pattern matching of interactive input from the console, such that searching and scanning interactive input for matches will return these matches immediately.
reflex::BoostMatcher extends the capabilities of Boost.Regex, which does not natively support streaming input:match_partial flag and boost::regex_iterator. Incremental matching can be used to support matching on (possibly infinite) streams. To use this method correctly, a buffer should be created that is large enough to hold the text for each match. The buffer must adjust with a growing size of the matched text, to ensure that long matches that do not fit the buffer are not discared.Boost.IOStreams with regex_filter loads the entire stream into memory which does not permit pattern matching of streaming and interactive input data.A reflex::BoostMatcher (or reflex::BoostPerlMatcher) engine is created from a boost::regex object, or string regex, and some given input for normal (Perl mode) matching:
Likewise, a reflex::BoostPosixMatcher engine is created from a boost::regex object, or string regex, and some given input for POSIX mode matching:
For input you can specify a string, a wide string, a file, or a stream object.
We use option "N" to permit empty matches when searching input with reflex::BoostMatcher::find.
You can convert an expressive regex of the form defined in Patterns to a regex that the boost::regex engine can handle:
The converter is specific to the matcher selected, i.e. reflex::BoostMatcher::convert, reflex::BoostPerlMatcher::convert, and reflex::BoostPosixMatcher::convert. The converters also translates Unicode \p character classes to UTF-8 patterns, converts bracket character classes containing Unicode, and groups UTF-8 multi-byte sequences in the regex string.
The converter throws a reflex::regex_error exception if conversion fails, for example when the regex syntax is invalid.
To compile your application, link your application against the libreflex library and -lboost_regex depending on your Boost installation):
c++ myapp.cpp -lreflex -lboost_regex
See Patterns for more details on regex patterns.
See The Input class for more details on the reflex::Input class.
See Methods and iterators for more details on pattern matching methods.
See Regex converters for more details on regex converters.
The reflex::StdMatcher class inherits reflex::PatternMatcher<std::regex> as a base. The reflex::StdEcmaMatcher and reflex::StdPosixMatcher are derived classes from reflex::StdMatcher:
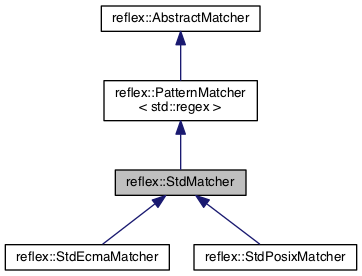
An instance of reflex::StdEcmaMatcher is initialized with regex syntax option std::regex::ECMAScript. This is also the default std::regex syntax.
An instance of reflex::StdPosixMatcher creates a POSIX AWK-based matcher. So that lazy quantifiers are not supported and the leftmost longest rule applies to pattern matching. This instance is initialized with the regex syntax option std::regex::awk.
The C++11 std::regex library does not support match_partial that is needed to match patterns on real streams with an adaptive internal buffer that grows when longer matches are made when more input becomes available. Therefore all input is buffered with the C++11 std::regex class matchers.
With respect to performance, as of this time of writing, std::regex matching is much slower than other matchers, slower by a factor 10 or more.
The std::regex syntax is more limited than PCRE2, Boost.Regex, and RE/flex. Also the matching behavior differs and cannot be controlled with mode modifiers:
. (dot) matches anything except \0 (NUL);\177 is erroneously interpreted as a backreference, \0177 does not match;\x7f is not supported in POSIX mode;\cX is not supported in POSIX mode;\Q..\E is not supported;(?imsux-imsux:φ);\A, \z, \< and \> anchors;\b and \B anchors in POSIX mode;(?:φ) in POSIX mode;"N" (nullable) may cause issues (std::regex match_not_null appears not to work as documented);interactive() is not supported.To work around these limitations that the std::regex syntax imposes, you can convert an expressive regex of the form defined in section Patterns to a regex that the std::regex engine can handle:
The converter is specific to the matcher selected, i.e. reflex::StdMatcher::convert, reflex::StdEcmaMatcher::convert, and reflex::StdPosixMatcher::convert. The converters also translates Unicode \p character classes to UTF-8 patterns, converts bracket character classes containing Unicode, and groups UTF-8 multi-byte sequences in the regex string.
The converter throws a reflex::regex_error exception if conversion fails, for example when the regex syntax is invalid.
To compile your application, link your application against the libreflex and enable std::regex with -std=c++11:
c++ -std=c++11 myapp.cpp -lreflex
See Patterns for more details on regex patterns.
See The Input class for more details on the reflex::Input class.
See Methods and iterators for more details on pattern matching methods.
See Regex converters for more details on regex converters.
The RE/flex framework includes a POSIX regex matching library reflex::Matcher that inherits the API from reflex::PatternMatcher<reflex::Pattern>:
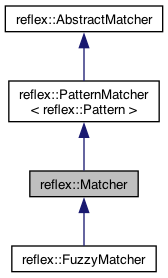
where the RE/flex reflex::Pattern class represents a regex pattern. Patterns as regex texts are internally compiled into deterministic finite state machines by the reflex::Pattern class. The machines are used by the reflex::Matcher for fast matching of regex patterns on some given input. The reflex::Matcher is faster than the PCRE2 and Boost.Regex matchers. The reflex::FuzzyMatcher subclass is included and performs approximate regex pattern matching, see The reflex::FuzzyMatcher class .
A reflex::Matcher engine is constructed from a reflex::Pattern object, or a string regex, and some given input:
The regex is specified as a string or a reflex::Pattern object. The reflex::Pattern object is passed by referene and must persist when the matcher is in use. See also The reflex::Pattern class below.
We use option "N" to permit empty matches when searching input with reflex::Matcher::find. Option "T=8" sets the tab size to 8 for Indent/nodent/dedent matching. Option "W" makes patterns match as words, i.e. a non-word Unicode character precedes and follows the pattern (only applies to reflex::Matcher and reflex::FuzzyMatcher.)
For input you can specify a string, a wide string, a file, or a stream object.
A regex string with Unicode patterns can be converted for Unicode matching as follows:
The converter is specific to the matcher and translates Unicode \p character classes to UTF-8 patterns, converts bracket character classes containing Unicode, and groups UTF-8 multi-byte sequences in the regex string.
To compile your application, link your application against the libreflex:
c++ myapp.cpp -lreflex
See Patterns for more details on regex patterns.
See The Input class for more details on the reflex::Input class.
See Methods and iterators for more details on pattern matching methods.
See Regex converters for more details on regex converters.
The reflex::FuzzyMatcher class is derived from reflex::Matcher to support approximate regex pattern matching. The approximation error is contrained by an "edit distance" which is one by default. The edit distance is also called Levenshstein distance. Instantiating a reflex::FuzzyMatcher takes an optional MAX paramter to contrain the edit distance permitted:
The regex is specified as a string or a reflex::Pattern object. The reflex::Pattern object is passed by referene and must persist when the matcher is in use. See also The reflex::Pattern class below.
The instantiated reflex::FuzzyMatcher class supports the same methods and features as the reflex::Matcher class, but with approximate pattern matching.
When a MAX edit distance parameter is specified, it may be combined with one or more of the following flags:
reflex::FuzzyMatcher::INS insertions permit extra character(s) in the inputreflex::FuzzyMatcher::DEL deletions permit missing character(s) in the inputreflex::FuzzyMatcher::SUB substitutions count as one editreflex::FuzzyMatcher::BIN ASCII/binary fuzzy matching, the default is Unicode (full Unicode matching requires the Unicode pattern converter shown further below)For example, to allow approximate pattern matches to include up to three character insertions, but no deletions or substitutions (allowing insertions only is actually the most efficient fuzzy matching possible):
To allow up to three insertions or deletions (note that a substitution counts as two edits: one insertion and one deletion):
When no flags are specified with MAX, fuzzy matching is performed with insertions, deletions, and substitutions, each counting as one edit. Newlines (\n) and NUL (\0) characters are never deleted or substituted to ensure that fuzzy matches do not extend the pattern match beyond the number of lines specified by the regex pattern
To support full Unicode fuzzy pattern matching, such as \p Unicode character classes, we first convert the regex pattern before using it as follows:
Fuzzy find() and split() perform a second pass over a fuzzy-matched pattern when the match has a nonzero error. This second pass checks if an exact match exists or if a better match exists that overlaps with the first pattern found.
For example, the pattern abc is found to fuzzy match all of the text aabc with one error (an extra a). The second pass of find() detects an exact match after skipping the first a. Likewise, the pattern abc is found to fuzzy match ababc with a match for aba with one error (substitution of c by an a). The second pass of find() detects an exact match after skipping ab in the text. This approach is faster than minimizing the edit distance when searching text, while returning exact matches when possible.
After a succesful fuzzy match or search with matches(), scan(), find() or split(), the method reflex::FuzzyMatcher::edits() returns the edit distance of the approximate pattern match, which is zero for an exact match.
The first character of the pattern must match when searching a corpus with the fuzzy find() method:
| Pattern | MAX | Fuzzy find matches these ... | ... but not these |
|---|---|---|---|
abc | 1 | abc, ab, ac, axc, axbc | a, axx, axbxc, bc |
año | 1 | año, ano, ao | anno, ño |
ab_cd | 2 | ab_cd, ab-cd, ab Cd, abCd | ab\ncd, Ab_cd, Abcd |
a[0-9]+z | 1 | a1z, a123z, az, axz | axxz, A123z, 123z |
Note that we can use . as the first character or make the first character optional with ? to "match fuzzily".
By contrast, the fuzzy matches() method to match a corpus from start to end does not have this requirement:
| Pattern | MAX | Fuzzy matches these ... | ... but not these |
|---|---|---|---|
abc | 1 | abc, ab, ac, Abc, xbc bc, axc, axbc | a, axx, Ab, axbxc |
año | 1 | año, Año, ano, ao, ño | anno |
ab_cd | 2 | ab_cd, Ab_Cd, ab-cd, ab Cd, Ab_cd, abCd | ab\ncd, AbCd |
a[0-9]+z | 1 | a1z, A1z, a123z, az, Az, axz, 123z | axxz |
Note that quoting text in patterns with \Q and \E fuzzy-matches the text. It does not escape fuzzy matching.
The reflex::Pattern class is used by reflex::Matcher and reflex::FuzzyMatcher for pattern matching. The reflex::Pattern class converts a regex pattern to an efficient FSM and takes a regex string and options to construct the FSM internally. The pattern instance is passed to a reflex::Matcher constructor:
The reflex::Pattern object is passed by referene and must persist when the matcher is in use. A new reflex::Pattern object may also be used to replace a matcher's current pattern at any time, see Flexible high-performance regex classes .
To improve performance, it is recommended to create a static instance of the pattern if the specified regex is fixed. This avoids repeated FSM construction at run time. Once constructed, the pattern object is constant and thread-safe to share among multiple threads with thread-local matchers instantiated.
The following options are combined in a string and passed to the reflex::Pattern constructor:
| Option | Effect |
|---|---|
b | bracket lists are parsed without converting escapes |
e=c; | redefine the escape character |
f=file.cpp; | save finite state machine code to file.cpp |
f=file.gv; | save deterministic finite state machine to file.gv |
i | case-insensitive matching, same as (?i)X |
m | multiline mode, same as (?m)X |
n=name; | use reflex_code_name for the machine (instead of FSM) |
q | Flex/Lex-style quotations "..." equals \Q...\E |
r | throw regex syntax error exceptions, otherwise ignore errors |
s | dot matches all (aka. single line mode), same as (?s)X |
x | inline comments, same as (?x)X |
w | display regex syntax errors before raising them as exceptions |
The compilation of a reflex::Pattern object into a FSM may throw an exception with option "r" when the specified regex has problems:
By default, the reflex::Pattern constructor solely throws the reflex::regex_error::exceeds_length and reflex::regex_error::exceeds_limits exceptions and silently ignores syntax errors.
The reflex::Matcher::convert, reflex::PCRE2Matcher::convert, reflex::PCRE2UTFMatcher::convert, reflex::BoostPerlMatcher::convert, reflex::BoostMatcher::convert, and reflex::BoostPosixMatcher::convert functions may throw a reflex_error exception such as for regex syntax error. See the next section for details.
The reflex::Pattern class has the following public methods:
| Method | Result |
|---|---|
assign(r,o) | (re)assign regex string r with string of options o |
assign(r) | (re)assign regex string r with default options |
=r | same as above |
size() | returns the number of top-level sub-patterns |
[0] | operator returns the regex string of the pattern |
[n] | operator returns the nth sub-pattern regex string |
reachable(n) | true if sub-pattern n is reachable in the FSM |
The assignment methods may throw exceptions, which are the same as the constructor may throw.
The reflex::Pattern::reachable method verifies which top-level grouped alternations are reachable. This means that the sub-pattern of an alternation has a FSM accepting state that identifies the sub-pattern. For example:
When executed this code prints:
regex = (a+)|(a) (a) is not reachable
For this example regex, (a) is not reachable as the pattern is subsumed by (a+). The reflex::Matcher::accept method will never return 2 when matching the input a and always return 1, as per leftmost longest match policy. The same observation holds for the reflex::Matcher::matches, reflex::Matcher::find, reflex::Matcher::scan, and reflex::Matcher::split method and functors. Reversing the alternations resolves this: (a)|(a+).
reflex::Pattern regex forms support capturing groups at the top-level only, i.e. among the top-level alternations.To work around limitations of regex libraries and to support Unicode matching, RE/flex offers converters to translate expressive regex syntax forms (with Unicode patterns defined in section Patterns ) to regex strings that the selected regex engines can handle.
The converters translate \p Unicode classes, translate character class set operations such as [a-z−−[aeiou]], convert escapes such as \X, and enable/disable (?imsux-imsux:φ) mode modifiers to a regex string that the underlying regex library understands and can use.
Each converter is specific to the regex engine. You can use a converter for the matcher of your choice:
std::string reflex::Matcher::convert(const std::string& regex, reflex::convert_flag_type flags) converts an enhanced regex for use with the RE/flex POSIX regex library;std::string reflex::PCRE2Matcher::convert(const std::string& regex, reflex::convert_flag_type flags) converts an enhanced regex for use with PCRE2;std::string reflex::PCRE2UTFMatcher::convert(const std::string& regex, reflex::convert_flag_type flags) converts an enhanced regex for use with PCRE2 native Unicode matching;std::string reflex::BoostMatcher::convert(const std::string& regex, reflex::convert_flag_type flags) converts an enhanced regex for use with Boost.Regex;std::string reflex::BoostPerlMatcher::convert(const std::string& regex, reflex::convert_flag_type flags) converts an enhanced regex for use with Boost.Regex in Perl mode;std::string reflex::BoostPosixMatcher::convert(const std::string& regex, reflex::convert_flag_type flags) converts an enhanced regex for use with Boost.Regex in POSIX mode;std::string reflex::StdMatcher::convert(const std::string& regex, reflex::convert_flag_type flags) converts an enhanced regex for use with C++ std::regex;std::string reflex::StdEcmaMatcher::convert(const std::string& regex, reflex::convert_flag_type flags) converts an enhanced regex for use with C++ std::regex in ECMA mode;std::string reflex::StdPosixMatcher::convert(const std::string& regex, reflex::convert_flag_type flags) converts an enhanced regex for use with C++ std::regex in POSIX mode;where flags is optional. When specified, it may be a combination of the following reflex::convert_flag flags:
| Flag | Effect |
|---|---|
reflex::convert_flag::none | no conversion |
reflex::convert_flag::basic | convert basic regular expression syntax (BRE) to extended regular expression syntax (ERE) |
reflex::convert_flag::unicode | ., \s, \w, \l, \u, \S, \W, \L, \U match Unicode, same as (?u) |
reflex::convert_flag::recap | remove capturing groups and add capturing groups to the top level |
reflex::convert_flag::lex | convert Flex/Lex regular expression syntax |
reflex::convert_flag::u4 | convert \uXXXX (shorthand for \u{XXXX}), may conflict with \u (upper case letter). |
reflex::convert_flag::notnewline | character classes do not match newline \n, e.g. [^a-z] does not match \n |
reflex::convert_flag::permissive | when used with unicode, produces a more compact FSM that tolerates some invalid UTF-8 sequences |
reflex::convert_flag::closing | match a ) literally without the presence of an opening ( |
The following reflex::convert_flag flags correspond to the common (?imsx) modifiers. These flags or modifiers may be specified, or both. Modifiers are removed from the converted regex if the regex library does not support them:
| Flag | Effect |
|---|---|
reflex::convert_flag::anycase | convert regex to ignore case, same as (?i) |
reflex::convert_flag::freespace | convert regex by removing all freespace-mode spacing, same as (?x) |
reflex::convert_flag::dotall | convert . (dot) to match all (match newline), same as (?s) |
reflex::convert_flag::multiline | adds/asserts if (?m) is supported for multiline anchors ^ and $ |
The following example enables Unicode matching by converting the regex pattern with the reflex::convert_flag::unicode flag:
The following example enables dotall mode to count the number of characters (including newlines) in the given example input:
Note that we could have used "\\X" instead to match any wide character without using the (?su) modifiers.
A converter throws a reflex::regex_error exception if conversion fails, for example when the regex syntax is invalid:
The RE/flex abstract matcher, that every other RE/flex matcher inherits, provides four operations for matching with an instance of a regex engine:
| Method | Result |
|---|---|
matches() | returns nonzero if the input from begin to end matches |
find() | search input and return nonzero if a match was found |
scan() | scan input and return nonzero if input at current position matches |
split() | return nonzero for a split of the input at the next match |
These methods return a nonzero *"accept"* value for a match, meaning the size_t accept() value that corresponds to a group capture (or one if no groups are used). The methods are repeatable, where the last three return additional matches.
The find, scan, and split methods are also implemented as input iterators that apply filtering tokenization, and splitting:
| Iterator range | Acts as a | Iterates over |
|---|---|---|
find.begin()...find.end() | filter | all matches |
scan.begin()...scan.end() | tokenizer | continuous matches |
split.begin()...split.end() | splitter | text between matches |
The matches() method returns a nonzero "accept" value (the size_t accept() group capture index value or the value 1 if no groups are used) if the given input from begin to the end matches the specified pattern.
For example, to match a UUID string with PCRE2:
When executed this code prints:
123e4567-e89b-12d3-a456-426655440000 is a string in UUID format
The matches() method returns the group capture index that can be used as a selector. For example:
See also Properties of a match.
The find() method and find.begin()...find.end() iterator range are used to search for a match in the given input.
The find() method returns a nonzero "accept" value (the size_t accept() group capture index value or the value 1 if no groups are used) for a match and zero otherwise.
For example, to find all words in a string with PCRE2 on UTF-8 input using reflex::PCRE2UTFMatcher:
When executed this code prints:
How now brown cow
The iterator range find.begin()...find.end() serves as an input filter.
For example, in C++11 we can use a range-based loop to loop over matches using the find iterator:
Iterators can be used with algorithms and other iterator functions. For example to count words in a string:
When executed this code prints:
4
The find() method returns the group capture index that can be used as a selector.
See also Properties of a match.
The scan() method and scan.begin()...scan.end() iterator range are similar to find but generate continuous matches in the given input.
The scan() method returns a nonzero "accept" value (the size_t accept() group capture index value or the value 1 if no groups are used) for a match and zero otherwise.
For example, to scan for words, spacing, and punctuation in a sentence with PCRE2:
When executed this code prints:
word space word space word space word other
The iterator range scan.begin()...scan.end() serves as an input tokenizer and produces continuous matches.
For example, tokenizing a string into a vector of numeric tokens:
When executed the code prints:
1 2 1 2 1 2 1 3
If the pattern does not match the input immediately succeeding a previous match, then the scan() method returns false and the iterator returns scan.end(). To determine if all input was scanned and end of input was reached, use the at_end() method, see Properties of a match.
See also Properties of a match.
The split() method and split.begin()...split.end() iterator range return text between matches in the given input.
The split() method returns a nonzero "accept" value (the size_t accept() group capture index value or the value 1 if no groups are used) of the matching text (that is, the text that comes after the split part) and zero otherwise.
When matches are adjacent then empty text is returned. Also the start of input and end of input return text that may be empty.
For example, to split text into words by matching non-words with PCRE2:
When executed this code prints:
'How' 'now' 'brown' 'cow' ''
This produces five text splits where the last text is empty because the period at the end of the sentence matches the pattern and empty input remains.
The iterator range split.begin()...split.end() serves as an input splitter.
For example, to display the contents of a text file while normalizing spacing:
reflex::PCRE2Matcher::Const::EMPTY to indicate that empty text after the split was found and matched. This special value is also returned by accept() and is also used with any other RE/flex matcher's split method.See also Properties of a match.
To obtain properties of a match, use the following methods:
| Method | Result |
|---|---|
accept() | returns group capture index (or zero if not captured/matched) |
text() | returns const char* to 0-terminated text match (ends in \0) |
strview() | returns std::string_view text match (preserves \0s) (C++17) |
str() | returns std::string text match (preserves \0s) |
wstr() | returns std::wstring wide text match (converted from UTF-8) |
chr() | returns first 8-bit char of the text match (str()[0] as int) |
wchr() | returns first wide char of the text match (wstr()[0] as int) |
chr_last() | returns last 8-bit char of the text match or 0 when empty |
wchr_last() | returns last wide char of the text match or 0 when empty |
chr_next() | returns next 8-bit char after the text match or EOF at end |
wchr_next() | returns next wide char after the text match or EOF at end |
pair() | returns std::pair<size_t,std::string>(accept(),str()) |
wpair() | returns std::pair<size_t,std::wstring>(accept(),wstr()) |
size() | returns the length of the text match in bytes |
wsize() | returns the length of the match in number of wide characters |
empty() | returns true if the match is empty (size() == 0) |
lines() | returns the number of lines in the text match (>=1) |
columns() | returns the number of columns of the text match (>=0) |
begin() | returns const char* to non-0-terminated text match begin |
end() | returns const char* to non-0-terminated text match end |
rest() | returns const char* to 0-terminated rest of input |
span() | returns const char* to 0-terminated match enlarged to span the line |
line() | returns std::string line with the matched text as a substring |
wline() | returns std::wstring line with the matched text as a substring |
more() | tells the matcher to append the next match (when using scan()) |
less(n) | cuts text() to n bytes and repositions the matcher |
lineno() | returns line number of the match, starting at line 1 |
columno() | returns column number of the match, starting at 0 |
lineno_end() | returns ending line number of the match, starting at line 1 |
columno_end() | returns ending column number of the match, starting at 0 |
bol() | returns const char* to non-0-terminated begin of matching line |
border() | returns byte offset from the start of the line of the match |
first() | returns input position of the first character of the match |
last() | returns input position + 1 of the last character of the match |
at_bol() | true if matcher reached the begin of a new line |
at_bob() | true if matcher is at the begin of input and no input consumed |
at_end() | true if matcher is at the end of input |
[0] | operator returns std::pair<const char*,size_t>(begin(),size()) |
[n] | operator returns n'th capture std::pair<const char*,size_t> |
The accept() method returns nonzero for a succesful match, returning the group capture index. The RE/flex matcher engine reflex::Matcher only recognizes group captures at the top level of the regex (i.e. among the top-level alternations), because it uses an efficient FSM for matching.
The text(), strview(), str(), and wstr() methods return the matched text. To get the first character of a match, use chr() or wchr(). The chr() and wchr() methods are much more efficient than str()[0] (or text()[0]) and wstr()[0], respectively. Likewise, chr_last() and wchr_last() return the last character of a match. To get the first next character in the input after a match, use chr_next() or wchr_next().
Note that empty() returns true if a match is empty. Normally, a match cannot be empty unless option "N" is specified to explicitly initialize a matcher, see The reflex::Matcher class , PCRE2 matcher classes , and Boost matcher classes .
The begin(), operator[0], and operator[n] return non-0-terminated strings. You must use end() with begin() to determine the span of the match. Basically, text() is the 0-terminated version of the string spanned by begin() to end(), where end() points the next character after the match, which means that end() = begin() + size(). Use the size of the capture returned by operator[n] to determine the end of the captured match.
The lineno() method returns the line number of the match, starting at line 1. The ending line number is lineno_end(), which is identical to the value of lineno() + lines() - 1.
The columno() method returns the column offset of a match from the start of the line, beginning at column 0. This method takes tab spacing and wide characters into account. The inclusive ending column number is given by columno_end(), which is equal or larger than columno() if the match does not span multiple lines. Otherwise, if the match spans multiple lines, columno_end() is the ending column of the match on the last matching line.
The starting byte offset of the match on a line is border() and the ending byte offset of the match is border() + size() - 1.
The lines() and columns() methods return the number of lines and columns matched, where columns() takes tab spacing and wide characters into account. If the match spans multiple lines, columns() counts columns over all lines, without counting the newline characters.
columno(), columno_end(), and columns() do not take the character display width of full-width and combining Unicode characters into account. It is recommended to use the wcwidth function or wcwidth.c to determine Unicode character widths.The rest() method returns the rest of the input character sequence as a 0-terminated char* string. This method buffers all remaining input to return the string.
The span() method enlarges the text matched to span the entire line and returns the matching line as a 0-terminated char* string without the \n.
The line() and wline() methods return the entire line as a (wide) string with the matched text as a substring. These methods can be used to obtain the context of a match.
span(), line(), and wline() invalidate the previous text(), strview(), begin(), bol(), and end() string pointers. Call these methods again to retrieve the updated pointer or call str() or wstr() to obtain a string copy of the match: reflex::AbstractMatcher::Const::BUFSZ. When this length is exceeded, the line's length before the match is truncated. This ensures that pattern matching binary files or files with very long lines cannot cause memory allocation exceptions.The matcher().more() method is used to create longer matches by stringing together consecutive matches in the input after scanning the input with the scan() method. When this method is invoked, the next match with scan() has its matched text prepended to it. The matcher().more() operation is often used in lexers and was introduced in Lex.
The less(n) method reduces the size of the matched text to n bytes. This method has no effect if n is larger than size(). The value of n should not be 0. The less(n) operation is often used in lexers and was introduced in Lex.
The first() and last() methods return the position in the input stream of the match, counting in bytes from the start of the input at position 0. If the input stream is a wide character sequence, the UTF-8 positions are returned as a result of the internally-converted UTF-8 wide character input.
All methods take constant time to execute except for str(), wstr(), pair(), wpair(), wsize(), lines(), columns(), and columno() that require an extra pass over the matched text.
In addition, the following type casts of matcher objects and iterators may be used for convenience:
size_t gives the matcher's accept() index.std::string is the same as invoking str()std::wstring is the same as invoking wstr().std::pair<size_t,std::string> is the same as pair().std::pair<size_t,std::wstring> is the same as wpair().The following example prints some of the properties of each match:
When executed this code prints:
accept: 1 text: How size: 3 line: 1 column: 0 first: 0 last: 3 accept: 1 text: now size: 3 line: 1 column: 4 first: 4 last: 7 accept: 1 text: brown size: 5 line: 1 column: 8 first: 8 last: 13 accept: 1 text: cow size: 3 line: 1 column: 14 first: 14 last: 17
Four public data members of a matcher object are accesible:
| Variable | Usage |
|---|---|
in | the reflex::Input object used by the matcher |
find | the reflex::AbstractMatcher::Operation functor for searching |
scan | the reflex::AbstractMatcher::Operation functor for scanning |
split | the reflex::AbstractMatcher::Operation functor for splitting |
Normally only the in variable should be used which holds the current input object of the matcher. See The Input class for details.
The functors provide begin() and end() methods that return iterators and hold the necessary state information for the iterators. A functor invocation essentially invokes the corresponding method listed in Methods and iterators .
To change a matcher's pattern or check if a pattern was assigned, you can use the following methods:
| Method | Result |
|---|---|
pattern(p) | set pattern to p (string regex or reflex::Pattern) |
has_pattern() | true if the matcher has a pattern assigned to it |
own_pattern() | true if the matcher has a pattern to manage and delete |
pattern() | get the pattern object associated with the matcher |
The first method returns a reference to the matcher, so multiple method invocations may be chained together.
To assign a new input source to a matcher or set the input to buffered or interactive, you can use the following methods:
| Method | Result |
|---|---|
input(i) | set input to reflex::Input i (string, stream, or FILE*) |
buffer() | buffer all input at once, returns true if successful |
buffer(n) | set the adaptive buffer size to n bytes to buffer input |
buffer(b, n) | use buffer of n bytes at address b with to a string of n-1 bytes (zero copy) |
interactive() | sets buffer size to 1 for console-based (TTY) input |
flush() | flush the remaining input from the internal buffer |
reset() | resets the matcher, restarting it from the remaining input |
reset(o) | resets the matcher with new options string o ("A?N?T?") |
The first method returns a reference to the matcher, so multiple method invocations may be chained together.
The following methods may be used to read the input stream provided to a matcher directly, even when you use the matcher's search and match methods:
| Method | Result |
|---|---|
input() | returns next 8-bit char from the input, matcher then skips it |
winput() | returns next wide character from the input, matcher skips it |
unput(c) | put 8-bit char c back unto the stream, matcher then takes it |
wunput(c) | put (wide) char c back unto the stream, matcher then takes it |
peek() | returns next 8-bit char from the input without consuming it |
skip(c) | skip input until character c (char or wchar_t) is consumed |
skip(s) | skip input until UTF-8 string s is consumed |
rest() | returns the remaining input as a non-NULL char* string |
The input(), winput(), and peek() methods return a non-negative character code and EOF (-1) when the end of input is reached.
A matcher reads from the specified input source using its virtual method size_t get(char *s, size_t n). This method is the same as invoking matcher().in.get(s, n) to directly read data from the reflex::Input source in, but also handles interactive input when enabled with matcher().interactive() to not read beyond the next newline character.
The following protected methods may be overriden by a derived matcher class to customize reading:
| Method | Result |
|---|---|
get(s, n) | fill s[0..n-1] with next input, returns number of bytes read |
wrap() | returns false (may be overriden to wrap input after EOF) |
When a matcher reaches the end of input, it invokes the virtual method wrap() to check if more input is available. This method returns false by default, but this behavior may be changed by overriding wrap() to set a new input source and return true, for example:
Note that the constructor in this example does not specify a pattern and input. To set a pattern for the matcher after its instantiation use the pattern(p) method. In this case the input does not need to be specified, which allows us to immediately force reading the sources of input that we assigned in our wrap() method.
For details of the reflex::Input class, see The Input class .
A matcher may accept several types of input, but can only read from one input source at a time. Input to a matcher is represented by a single reflex::Input class instance that the matcher uses internally.
An input object is constructed by specifying a string, a file, or a stream to read from. You can also reassign input to read from new input.
More specifically, you can pass a std::string, char*, std::wstring, wchar_t*, FILE*, or a std::istream to the constructor.
A FILE* file descriptor is a special case. The input object handles various file encodings. If a UTF Byte Order Mark (BOM) is detected then the UTF input will be normalized to UTF-8. When no UTF BOM is detected then the input is considered plain ASCII, binary, or UTF-8 and passed through unconverted. To override the file encoding when no UTF BOM was present, and normalize Latin-1, ISO-8859-1 through ISO-8859-15, CP 1250 through 1258, CP 437, CP 850, CP 858, KOI8, MACROMAN, EBCDIC, and other encodings to UTF-8, see FILE encodings.
An input object constructed from an 8-bit string char* or std::string just passes the string to the matcher engine. The string should contain UTF-8 when Unicode patterns are used.
An input object constructed from a wide string wchar_t* or std::wstring translates the wide string to UTF-8 for matching, which effectively normalizes the input for matching with Unicode patterns. This conversion is illustrated below. The copyright symbol © with Unicode U+00A9 is matched against its UTF-8 sequence C2 A9 of ©:
To ensure that Unicode patterns in UTF-8 strings are grouped properly, use Regex converters , for example as follows:
Here we made the converted pattern static to avoid repeated conversion and construction overheads.
char*, wchar_t*, and std::wstring strings cannot contain a \0 (NUL) character and the first \0 terminates matching. To match strings and binary input that contain \0, use std::string or std::istringstream.An input object constructed from a std::istream (or a derived class) just passes the input text to the matcher engine. The stream should contain ASCII and may contain UTF-8.
File content specified with a FILE* file descriptor can be encoded in ASCII, binary, UTF-8/16/32, ISO-8859-1 through ISO-8859-15, CP 1250 through 1258, CP 437, CP 850, CP 858, or EBCDIC.
A UTF Byte Order Mark (BOM) is detected in the content of a file scanned by the matcher, which enables UTF-8 normalization of the input automatically.
Otherwise, if no file encoding is explicitly specified, the matcher expects raw UTF-8, ASCII, or plain binary by default. File formats can be decoded and translated to UTF-8 on the fly for matching by means of specifying encodings.
The current file encoding used by a matcher is obtained with the reflex::Input::file_encoding() method, which returns an reflex::Input::file_encoding constant of type reflex::Input::file_encoding_type:
The null_data encoding type converts between NUL (zere byte) and LF (\n) to support input from tools that output NUL for newlines, such as xargs -0.
To specify a file encoding when assigning a file to be read, use reflex::Input(file, enc) with enc one of the encoding constants shown in the table above.
For example, reflex::Input::file_encoding::latin supports files with ISO-8859-1 content. This way you can match its content using Unicode patterns, since the RE/flex matcher engines internally normalize the specified encodings to UTF-8 for pattern matching:
This sets the input encoding to ISO-8859-1, but only if no UTF BOM was detected on the standard input we are reading from. The encoding of an input file specified as a FILE* argument when the file has a UTF BOM cannot be changed. The input of UTF-encoded files is normalized to UTF-8 when read.
To define a custom code page to normalize the input to Unicode, define a code page table with 256 entries that maps each 8-bit input character to a 16-bit Unicode character (UCS-2). Then use reflex::Input::file_encoding::custom with a pointer to your code page to construct an input object. For example:
This example translates all control characters and characters above 127 to spaces before matching.
To obtain the properties of an input source use the following methods:
| Method | Result |
|---|---|
size() | size in bytes of the remaining input, zero when EOF or unknown |
good() | input is available to read (no error and not EOF) |
eof() | end of input (but use only at_end() with matchers!) |
cstring() | the current const char* (of a std::string) or NULL |
wstring() | the current const wchar_t* (of a std::wstring) or NULL |
file() | the current FILE* file descriptor or NULL |
istream() | a std::istream* pointer to the current stream object or NULL |
We can use a reflex::Input object as a std::streambuf and pass it to a std::istream. This is useful when a std::istream is required where a reflex::Input object cannot be directly used. The std::istream automatically normalizes the input to UTF-8 using the underlying reflex::Input object. For example:
The reflex::Input object may be created from strings, wide strings, streams, and FILE* values. These are readable as a std::istream via reflex::Input::streambuf that returns normalized UTF-8 characters. For FILE* values we can specify FILE encodings to normalize the encoded input to UTF-8.
Keep in mind that adding a std::istream with reflex::Input::streambuf layer on top of the efficient reflex::Input class will impact file reading performance, especially because reflex::Input::streambuf is unbuffered (despite its name). When performance is important, use the buffered version reflex::BufferedInput::streambuf:
Because the buffered vesion reads ahead to fill its buffer, the buffered version may not be suitable for interactive input.
See also Windows CRLF pairs.
Reading files in Windows "binary mode" is recommended when the file is encoded in UTF-16 or UTF-32. Reading a file in the default "text mode" replaces CRLF by LF and interprets ^Z (0x1A) as EOF. Because a ^Z code may be part of a UTF-16 or UTF-32 multibyte sequence, this can cause premature EOF on Windows machines. The latest RE/flex releases automatically switch FILE* input to binary mode on Windows systems when the file is encoded in UTF-16 or UTF-32.
In addition, DOS files and other DOS or Windows input sources typically end lines with CRLF byte pairs, see Files with CRLF pairs . Reading a file in binary mode retains these CRLF pairs.
To automatically replace CRLF by LF when reading files in binary mode on Windows you can use the reflex::Input::dos_streambuf class to construct a std::istream object. This normalized stream can then be used as input to a RE/flex scanner or to a regex matcher:
Once the stream object is created it can be used to create a new input object for a RE/flex scanner, for example:
or for a regex matcher that uses PCRE2 or Boost.Regex:
Note that when the input is a FILE*, CRLF pairs are replaced by LF and UTF-16/32 encodings are automatically normalized to UTF-8 (when a UTF BOM is present in the file or you can specify FILE encodings).
reflex::Input::size method returns the number of bytes available that includes CRLF pairs. The actual number of bytes read may be smaller after replacing CRLF by LF.When performance is important, use the buffered version reflex::BufferedInput::dos_streambuf:
Because the buffered vesion reads ahead to fill its buffer, the buffered version may not be suitable for interactive input:
See also Input streambuf.
This section includes several examples to demonstrate the concepts discussed.
This example illustrates the find and split methods and iterators with a RE/flex reflex::Matcher and a reflex::BoostMatcher using a C++11 range-based loop:
When executed this code prints:
Monty at 1,0 spans 0..5 Python at 2,1 spans 7..13 4 words Monty Python's Flying Circus Circus Flying Monty Python's
This example shows how a URL can be matched by using two patterns: one pattern to extract the host:port/path parts and another pattern to extract the query string key-value pairs in a loop. A PCRE2 matcher or a Boost.Regex matcher may be used, since both support group captures.
See also Example 8 below for a more powerful URL pattern matcher.
This example shows how input can be reassigned in each iteration of a loop that matches wide strings against a word pattern \w+:
When executed this code prints:
Monty, Flying, Circus,
This example counts the number of words, lines, and chars from the std::cin stream:
This example tokenizes a string by grouping the subpatterns in a regex and by using the group index of the capture obtained with accept() in a C++11 range-based loop:
When executed this code prints:
Token = 1: matched 'cats' with '(\\w*cat\\w*)' Token = 4: matched ' ' with '(.)' Token = 3: matched 'love' with '(\\w+)' Token = 4: matched ' ' with '(.)' Token = 2: matched 'hotdogs' with '(\\w*dog\\w*)' Token = 4: matched '!' with '(.)'
This example reads a file with embedded credit card numbers to extract. The numbers are sorted into five sets for each type of major credit card:
When executed this code prints:
0: 5212345678901234 1: 4123456789012 1: 4123456789012345 2: 371234567890123 3: 601112345678901234 4: 38812345678901
The RE/flex matcher engine reflex::Matcher only recognizes group captures at the top level of the regex (i.e. among the top-level alternations), because it uses an efficient FSM for matching.
By contrast, the PCRE2 matcher can capture groups within a regex:
The PCRE2 and Boost.Regex libraries also support group captures and partial matches, but that feature appears to be broken with Boost.Regex, so all input must be buffered when Boost.Regex is used:
This is a more advanced example, in which we will use the reflex::BoostMatcher class to decompose URLs into parts: the host, port, path, optional ?-query string key=value pairs, and an optional #-anchor.
To do so, we change the pattern of the matcher to partially match each of the URL's parts and also use input() to check the input character:
Note that there are two ways to split the query string into key-value pairs. Both methods are shown in the two #if branches in the code above, with the first branch disabled with #if 0.
When executing
./url 'https://localhost:8080/test/me?name=reflex&license=BSD-3'
this code prints:
host: localhost port: 8080 path: test/me query key: name, value: reflex query key: license, value: BSD-3
This example shows how a FILE* file descriptor is used as input. The file encoding is obtained from the UTF BOM, when present in the file. Note that the file's state is accessed through the matcher's member variable in:
The default encoding is reflex::Input::file_encoding::plain when no UTF BOM is detected at the start of the input file. The encodings reflex::Input::file_encoding::latin, reflex::Input::file_encoding::cp1252, reflex::Input::file_encoding::cp437, reflex::Input::file_encoding::cp850, reflex::Input::file_encoding::ebcdic are never detected automatically, because plain encoding is implicitly assumed to be the default encoding. To convert these files, set the file encoding format explicitly in your code. For example, if you expect the source file to contain ISO-8859-1 8-bit characters (ASCII and the latin-1 supplement) then set the default file encoding to reflex::Input::file_encoding::latin as follows:
This sets the file encoding to ISO-8859-1, but only if no UTF BOM was detected in the file. Files with a UTF BOM are always decoded as UTF, which cannot be overruled.
For backward compatibility with Flex, option −−flex defines macros to expand yyin, yyout, yylineno, yytext, and yyleng. The macro expansion depends on the −−bison option or −−bison-locations, −−bison-cc and so on.
When used with −−flex, option −−bison generates global "yy" variables and functions, see Bison and thread-safety for details. This means that yytext, yyleng, and yylineno are global variables. More specifically, the following declarations are generated with −−flex and −−bison:
Note that yyin is not a global variable, because the yyin macro expands to a pointer to the reflex::Input of the matcher. This offers advanced input handling capabilities with reflex::Input that is more useful compared to the traditional global FILE *yyin variable.
However, the following declaration, when present in a Lex/Flex lexer specification, may cause a compilation error:
Option −−yy enables −−flex and −−bison. In addition, this option generates the following declarations to define the yyin and yyout as global FILE* type variables:
Note that without option −−yy, when options −−flex and −−bison are used, yyin is a pointer to a reflex::Input object. This means that yyin is not restricted to FILE* types and accepts files, steams and strings:
See Switching input sources .
To use Flex' yy functions in your scanner's actions, use option −−flex for Flex compatibility (see also previous section).
In addition, note that by default the reflex command generates a reentrant C++ scanner class, unless option −−bison is used. This means that by default all yy functions are scanner class methods, not global functions. This obviously means that yy functions cannot be globally invoked, e.g. from your parser. These are the alternatives:
yy functions like Flex with option −−yy (or −−flex and −−bison). This approach is not thread safe.yy functions, see the list of scanner methods listed in The rules section.#define YY_SCANNER (redefine) in your parser and in other parts of the program that need to invoke yy functions: yyinput() macro expands to YY_SCANNER.input(), where YY_SCANNER is normally (*this), i.e. the current scanner object, or YY_SCANNER is the global scanner object/state when option −−bison is used to generate global yy variables and functions stored in the global YY_SCANNER object.It may be tempting to write a lexer pattern with . (dot) as a wildcard in a lexer specification, but beware that in Unicode mode enabled with %option unicode or with modifier (?u:φ), the dot matches any code point, including code points outside of the valid Unicode character range and invalid overlong UTF-8 (except that it won't match newline unless %option dotall is specified.) The reason for this design choice is that a lexer should be able to implement a "catch all else" rule to report errors in the input:
The dot in Unicode mode lexing is self-synchronizing and consumes input up to the next valid ASCII or Unicode character, allowing the lexer to continue when desired.
We can use .|\n or %option dotall to also catch \n newlines besides catching unmatched input and invalid UTF-8/16/32 encodings.
If dot in Unicode mode with %option unicode would be restricted to match valid Unicode only, then the action above will never be triggered when invalid input is encountered. Because all non-dot regex patterns are valid Unicode in RE/flex, it would be impossible to write a "catch all else" rule that catches input format errors!
Because the . is "permissive" by design with %option unicode, multiple . dots in sequence such as ... can actually surprisingly match a single multi-byte Unicode character by matching its three individual UTF-8 bytes.
To accept only valid Unicode input in regex patterns, make sure to avoid . (dot) and use \p{Unicode} or \X instead, and reserve dot to catch anything, such as invalid UTF encodings.
Furthermore, before matching any input, invalid UTF-16 input is detected automatically by the reflex::Input class and replaced with the REFLEX_NONCHAR code point U+200000 that lies outside the valid Unicode range. This code point is never matched by non-dot regex patterns and is easy to detect by a regex pattern with a dot and a corresponding error action as shown above.
Note that character classes written as bracket lists may produce invalid Unicode ranges when used improperly. This is not a problem for matching, but may prevent rejecting surrogate halves that are invalid Unicode. For example, [\u{00}-\u{10FFFF}] obviously includes the invalid range of surrogate halves [\u{D800}-\u{DFFF}]. You can always remove surrogate halves from any character class by intersecting the class with [\p{Unicode}], that is [...&&[\p{Unicode}]]. Furthermore, character class negation with ^ results in classes that are within range U+0000 to U+10FFFF and excludes surrogate halves.
When your scanner or parser encounters an error in the input, the scanner or parser should report it and attempt to continue processing the input by recovering from the error condition. Most compilers recover from an error to continue processing the input until a threshold on the maximum number of errors is exceeded.
In our lexer specification of a scanner, we may define a "catch all else" rule with pattern . to report an unmatched "mystery character" that is not recognized. For example:
Beware that a . (dot) matches any character or byte, including invalid Unicode. See also Invalid UTF encodings and the dot pattern .
The error message indicates the offending line number with lineno() and prints the problematic line of input using matcher().line(). The position on the line is indicated with an arrow placed below the line at offset columno() from the start of the line, where columno() takes tabs and wide characters into account.
This error message does not take the window width into account, which may result in misplacing the arrow when the line is too long and overflows onto the next rows in the window, unless changes are made to the code to print the relevant part of the line only.
There are other ways to indicate the location of an error, for example as --> <-- and highlighting the error using the ANSI SGI escape sequence for bold typeface:
This prints the start of the line up to the mismatching position on the line returned by border(), followed by the highlighted "mystery character". Beware that this can be a control code or invalid Unicode code point, which should be checked before displaying it.
This scanner terminates when 10 lexical errors are encountered in the input, as defined by max_errors.
By default, Bison invokes yyerror() (or yy::parser::error() with Bison-cc parsers) to report syntax errors. However, it is recommended to use Bison error productions to handle and resolve syntax errors intelligently by synchronizing on tokens that allow the parser to continue, for example on a semicolon in a Bison-bridge parser:
%pure-parser is deprecated and replaced with %define api.pure.We keep track of the number of errors by incrementing lexer->errors. When the maximum number of lexical and syntax errors is reached, we bail out.
The line of input where the syntax error occurs is reported with yyerror() for the Bison-bridge parser:
With option −−flex, the definitions part of the lexer specification is updated as follows:
And the yyerror() function is updated as follows:
%pure-parser is deprecated and replaced with %define api.pure.These examples assume that the syntax error was detected immediately at the last token scanned and displayed with lexer->str(), which may not always be the case.
With Bison-bridge & locations parsers (and optionally −−flex), we obtain the first and the last line of an error and we can use this information to report the error. For example as follows:
Because we use Flex-compatible reentrant functions yy_create_buffer(), yypush_buffer_state(), and yypop_buffer_state() that take an extra scanner argument, we also use options −−flex and −−reentrant in addition to −−bison-bridge and −−bison-locations to generate the reentrant scanner for the example shown above.
Similarly, with Bison-complete & locations parsers, syntax errors can be reported as follows (without option −−flex):
If option −−exception is specified with a lexer specification, for example as follows:
then we should make sure to consume some input in the exception handler to advance the scanner forward to skip the offending input and to allow the scanner to recover:
Error reporting can be combined with Bison Lookahead Correction (LAC), which is enabled with:
For more details on Bison error messaging, resolution, and LAC, please see the Bison documentation.
The RE/flex scanners and regex matchers use an internal buffer with UTF-8 encoded text content to scan wide strings and UTF-16/UTF-32 input. This means that Unicode input is normalized to UTF-8 prior to matching. This internal conversion is independent of the current locale and is performed automatically by the reflex::Input class that passes the UTF-8-normalized input to the matchers.
Furthermore, RE/flex lexers may invoke the wstr(), wchr(), and wpair() methods to extract wide string and wide character matches. These methods are also independent of the current locale.
This means that setting the locale in an application will not affect the performance of RE/flex scanners and regex matchers.
As a side note, to display wide strings properly and to save wide strings to UTF-8 text files, it is generally recommended to set the UTF-8 locale. For example:
This displays wide string matches in UTF-8 on most consoles and terminals, but not on all systems (I'm looking at you, Mac OS X terminal!) Instead of std::wcout we can use std::cout instead to display UTF-8 content directly:
Scanning files encoded in ISO-8859-1 by a Unicode scanner that expects UTF-8 will cause the scanner to misbehave or throw errors.
Many text files are still encoded in ISO-8859-1 (also called latin-1). To set up your scanner to safely scan ISO-8859-1 content when your scanner rules use Unicode (with the −−unicode option and your patterns that use UTF-8 encodings), set the default file encoding to latin:
This scans files from standard input that are encoded in ISO-8859-1, unless the file has a UTF Byte Order Mark (BOM). When a BOM is detected the scanner switches to UTF scanning.
See FILE encodings to set file encodings.
DOS files and other DOS or Windows input sources typically end lines with CRLF byte pairs. There are two ways to effectively deal with CRLF pairs:
reflex::Input::dos_streambuf to automatically convert Windows CRLF pairs by creating a std::istream for the specified reflex::Input::dos_streambuf. Due to the extra layer introduced in the input processing stack, this option adds some overhead but requires no changes to the patterns and application code.\n and \r\n to allow CRLF line endings. This is option is fast to process input, but requires specialized patterns and the matched multi-line text will include \r (CR) characters that may need to be dealt with by the application code.To rewrite your patterns to support CRLF end-of-line matching:
\n in patterns by \r?\n..* in patterns by ([^\n\r]|\r[^\n])* to match any non-newline characters. Likewise replace .+ by its longer version. Note that a single . can still be used in patterns but may match a \r just before a \n when a CRLF is encountered.With the above changes, reading files on Windows systems in "binary mode" is recommended, i.e. open FILE* files with the "rb" mode.
Reading a file in the default "text mode" interprets ^Z (0x1A) as EOF. The latest RE/flex releases automatically switch FILE* input to binary mode on Windows systems when the file is encoded in UTF-16 or UTF-32, but not UTF-8.
Old Macintosh OS file formats prior to Mac OS X use CR to end lines instead of LF. To automatically read and normalize files encoded in MacRoman containing CR as newlines, you can use the reflex::Input::file_encoding::macroman file encoding format. This normalizes the input to UTF-8 and translates CR newlines to LF newlines. See FILE encodings for details.
Alternatively, you can define a custom code page to translate CR to LF without normalizing to UTF-8:
Then use the input object to read stdin or any other FILE*. See also FILE encodings.
Repetitions (*, +, and {n,m}) and the optional pattern (?) are greedy, unless marked with an extra ? to make them lazy. Lazy repetitions are useless when the regex pattern after the lazy repetitions permits empty input. For example, .*?a? only matches one a or nothing at all, because a? permits an empty match.
See also POSIX versus Perl matching .
This C/C++ trigraph problem work-around does not apply to lexer specifications that the reflex command converts while preventing trigraphs.
Trigraphs in C/C++ strings are special tripple-character sequences, beginning with two question marks and followed by a character that is translated. For example, "x??(y|z)" is translated to "x[y|z)".
Fortunately, most C++ compilers ignore trigraphs unless in standard-conforming modes, such as -ansi and -std=c++98.
When using the lazy optional pattern φ?? in a regex C/C++ string for pattern matching with one of the RE/flex matchers for example, use φ?\? instead, which the C/C++ compiler translates to φ??.
Otherwise, lazy optional pattern constructs will appear broken.
The state of the input object reflex::Input changes as the scanner's matcher consumes more input. If you switch to the same input again (e.g. with in(i) or switch_stream(i) for input source i), a portion of that input may end up being discarded as part of the matcher's internal buffer is flushed when input is assigned. Therefore, the following code will not work because stdin is flushed repeatedly:
If you need to read a file or stream again, you have two options:
push_matcher(m) or yypush_buffer_state(m) to start using a new matcher m, e.g. created with reflex::Matcher m = new_matcher(i) to consume the specified input i. Restore the original matcher with pop_matcher() or yypop_buffer_state(). See also Multiple input sources .FILE* input is checked against an UTF BOM at the start of a file, which means that you cannot reliably move to an arbitrary location in the file to start reading when the file is encoded in UTF-8, UTF-16, or UTF-32.RE/flex uses its own header file reflex/flexlexer.h for compatibility with Flex, instead of the Flex file FlexLexer.h. The latter is specific to Flex and cannot be used with RE/flex. You should not have to include FlexLexer.h but if you do, use:
The FlexLexer class defined in reflex/flexlexer.h is the base class of the generated yyFlexLexer class. A name for the generated lexer class can be specified with option −−lexer=NAME.
Option -I for interactive input generates a scanner that uses fgetc() to read input from a FILE* descriptor (stdin by default). Interactive input is made more user-friendly with the GNU readline library that provides basic line editing and a history mechanism.
To use readline() in your lexer, call readline() in your Lexer's constructor and in the wrap() method as follows:
With option −−flex you will need to replace wrap() by a Flex-like yywrap() and change it to return 0 on success:
The rules can be matched as usual, where \n matches the end of a line, for example:
This section is updated. RE/flex 5.4 and greater support non-blocking FILE* input by waiting until input becomes available. For this to work, the reflex::Input::Handler::operator()() method has completely changed in RE/flex 5.4. When a custom handler is defined, it is always invoked after a FILE* read. The handler can be used to inspect the input before being passed on to the regex matcher. It can be used to update an in-progress bar in a dialog window, for example. It can be used to control non-blocking input, including exiting with EOF when a time out occurs.
The input handler is derived from the reflex::Input::Handler abstract base class as follows:
When len is zero, no input could be read on a non-blocking FILE*. This may be temporary or an actual EOF. A blocking FILE* always has a zero len on EOF. Returning zero from the handler will let reflex::Input wait indefinitely until input becomes available or stops reading on EOF.
If a timeout is desired, then this can be implemented in the custom handler as follows:
A FILE* stream is set to non-blocking mode in Unix/Linux with fcntl(). A custom handler is registered with reflex::Input::set_handler() and removed with a NULL handler (when new input is assigned, a handler is always removed):
The custom event handler can also be used to detect and clear FILE* errors by checking if an error conditions exist on the FILE* input indicated by ferror(). When the handler functor returns zero, it indicates EOF and the remaining input is ignored.
fcntl() non-blocking.Some hints when dealing with undefined symbols and link errors when building RE/flex applications:
Compilation requires libreflex which is linked using compiler option -lreflex:
c++ ... -lreflex
If libreflex was not installed on your system then header files cannot be found and linking with -lreflex fails. Instead, you can specify the include path and link the library with:
c++ -I<path>/reflex/include ... -L<path>/reflex/lib -lreflex
where <path> is the directory path to the top directory of the downloaded RE/flex package.
reflex/lib and the reflex/unicode directories of the RE/flex download package. The header files are located in the reflex/include/reflex directory.libpcre2-8: c++ ... -lreflex -lpcre2-8
libboost_regex: c++ ... -lreflex -lboost_regex
std::regex matching engine, you should compile the source code as C++11: c++ -std=c++11 ... -lreflex
reflex tool, the generated lex.yy.cpp lexer logic should be compiled and linked with your application. We use reflex option −−header-file to generate lex.yy.h with the lexer class to include in the source code of your lexer application.RE/flex scanners generated with reflex can be linked against a minimized version of the RE/flex library libreflexmin:
c++ ... -lreflexmin
The regex Unicode converters and the Unicode tables that are not used at run time are excluded from the minimized library.
If the RE/flex library is not installed, for example when cross-compiling a RE/flex scanner to a different platform, then compile directly from the RE/flex C++ source files located in the reflex/lib and reflex/include directories as follows:
c++ -I. -Iinclude lex.yy.cpp lib/debug.cpp lib/error.cpp \
lib/input.cpp lib/matcher.cpp lib/pattern.cpp lib/utf8.cpp lib/simd.cpp
This compiles the code without SIMD optimizations, despite compiling lib/simd.cpp. SIMD intrinsics for SSE/AVX and ARM NEON/AArch64 are used to speed up string search and newline detection and counting in the library. These optimizations are for the most part applicable to speed up searching with the reflex::Matcher::find() method.
To compile with NEON/AArch64 optimizations applied (omit -mfpu=neon for AArch64):
c++ -DHAVE_NEON -mfpu=neon -I. -Iinclude lex.yy.cpp lib/debug.cpp lib/error.cpp \
lib/input.cpp lib/matcher.cpp lib/pattern.cpp lib/utf8.cpp lib/simd.cpp
To compile with SSE2 optimizations applied:
c++ -DHAVE_SSE2 -msse2 -I. -Iinclude lex.yy.cpp lib/debug.cpp lib/error.cpp \
lib/input.cpp lib/matcher.cpp lib/pattern.cpp lib/utf8.cpp lib/simd.cpp
To compile with AVX2 optimizations applied and run-time detection of AVX2 using SSE2 as a fallback optimization when the CPU does not support AVX2:
c++ -DHAVE_AVX2 -mavx2 -I. -Iinclude lex.yy.cpp lib/debug.cpp lib/error.cpp \
lib/input.cpp lib/matcher.cpp lib/pattern.cpp lib/utf8.cpp lib/simd.cpp \
lib/matcher_avx2.cpp lib/simd_avx2.cpp
To compile with AVX512BW optimizations applied and run-time detection of AVX512BW using AVX2 or SSE2 as a fallback optimization when the CPU does not support AVX512BW:
c++ -DHAVE_AVX512BW -mavx512bw -I. -Iinclude lex.yy.cpp lib/debug.cpp lib/error.cpp \
lib/input.cpp lib/matcher.cpp lib/pattern.cpp lib/utf8.cpp lib/simd.cpp \
lib/matcher_avx2.cpp lib/matcher_avx512bw.cpp lib/simd_avx2.cpp lib/simd_avx512bw.cpp
Runtime memory usage is largely determined by two entities, the pattern DFA and the input buffer:
reflex option −−full to create a statically-allocated table DFA for the scanner's regular expression patterns or option −−fast to generate a direct-coded DFA. Without one of these options, by default a DFA is created at runtime and stored in heap space.-DREFLEX_BUFSZ=16384 to override the internal buffer reflex::AbstractMatcher::Const::BUFSZ size. By default, the buffer size is 256K, which is optimal for high-performance file searching and tokenization. The buffer is a sliding window over the input, i.e. input files may be much larger than the buffer size. A reasonably small REFLEX_BUFSZ is 16384 for a 16K buffer. A small buffer automatically expands to accommodate larger pattern matches. However, when using the line() and wline() methods, very long lines may not fit and the return string values of line() and wline() may be truncated as a result. Furtheremore, a small buffer increase processing time, i.e. to frequently move the buffered window along a file and increases the cost to decode UTF-16/32 into UTF-8 multibyte sequences.REFLEX_BUFSZ should not be less than 4096.All RE/flex matchers, including reflex::Matcher, reflex::PCRE2Matcher, reflex::BoostMatcher, reflex::StdMatcher and reflex::FuzzyMatcher, use an internal buffer of 256K. This buffer is used to search and match input by copying the specified input into this buffer. This allows the input to be modified, such as writing a zero byte to make the character strings returned by text() and rest() always 0-terminated. The buffer shifts to handle input larger than 256K by consuming the input in blocks of up to 256K at a time. The buffer only grows in size to accomodate pattern matches that are longer than 256K, which will not happen when you specify regex patterns that do not match byte sequences longer than 256K, e.g. when patterns exclude \n (newline) characters when the input consists of regular lines of text.
When the data you want to search resides in memory, you can eliminate the overhead of buffer copying as follows. Before searching or matching the data, specify the memory region you want to search at address b of size n with reflex::Matcher::buffer(b, n + 1). Note that an extra byte after the end of the data must be avalable in this memory region, hence we pass n + 1 to search n bytes. The final byte at the end of the memory region will be set to zero when unput(c), wunput(), text(), rest() or span() is used. But otherwise the memory region, including the final byte, remains completely untouched and you can safely specify n + 1 even when the allocated region has n bytes of data.
For example:
See also Flexible high-performance regex classes (towards the end of the section) and Switching input sources on zero copy overhead with RE/flex lexers.
When a matcher object is constructed as a temporary in a range-based loop, it will be destroyed before we actually use it in the loop to find all matches. This means that the following example crashes:
Instead, write:
Note that some C++23 compilers handle this just fine as support for range-based loop temporaries was proposed to the C++ standards committee.
The RE/flex library includes some functions to convert UTF-8:
size_t reflex::utf8(int wc, char *buf) converts UCS-4 wide character code point wc and stores the UTF-8 sequence in buffer buf[] without adding a terminating \0 to the buffer, returning the length of the sequence between 1 and 6, where buf[] must be at least 6 bytes long.int reflex::utf8(const char *s, const char **r) returns the first UCS-4 wide character code point in the UTF-8 string s and sets r when not NULL to point to the next character in s.std::wstring reflex::wcs(const char *s, size_t n) returns the wide string converted from UTF-8 string s of length n.std::wstring reflex::wcs(const std::string &s) returns the wide string converted from UTF-8 string s.Example:
Certain Unicode character classes are very large, see table below. Combining them with other patterns may grow the DFA tables quickly in size, sometimes even exponentially in size, which is unlikely but theoretically possible.
Before using large Unicode classes in regex patterns, consider alternatives that are smaller in size. A character class that has fewer character blocks is less complex than a character class that has many character blocks (a block contains a contiguous range of code points).
The table below lists the largest Unicode classes specified with \p{Class} in comparison to the POSIX ASCII cases that don't have many characters, when defined:
| Unicode class | esc | chars | blocks | POSIX | chars |
|---|---|---|---|---|---|
Alnum | 4744 | 213 | [[:alnum:]] | 62 | |
Alpha | 4064 | 150 | [[:alpha:]] | 52 | |
C, Cntrl, Other | 235 | 23 | [[:cntrl:]] | 33 | |
Cf, Format | 170 | 21 | |||
Common | 8306 | 173 | |||
CsIdentifierPart | 140259 | 782 | |||
CsIdentifierStart | 136973 | 669 | |||
Graph | 1111810 | 25 | [[:graph:]] | 94 | |
JavaIdentifierPart | 140378 | 799 | |||
JavaIdentifierStart | 137035 | 684 | |||
L, Letter | 136726 | 660 | |||
L& | 4095 | 143 | |||
Latin | 1481 | 39 | |||
Ll, Lower, Lowercase_Letter | \l | 2233 | 658 | [[:lower:]] | 26 |
Lm, Modifier_Letter | 397 | 71 | |||
Lo, Other_Letter | 132234 | 511 | |||
Lt, Titlecase_Letter | 31 | 10 | |||
Lu, Upper, Uppercase_Letter | \u | 1831 | 646 | [[:upper:]] | 26 |
M, Mark | 2450 | 310 | |||
Mc, Spacing_Combining_Mark | 452 | 182 | |||
Me, Enclosing_Mark | 91 | 1 | |||
Mn, Non_Spacing_Mark | 1985 | 346 | |||
N, Number | 1831 | 137 | |||
Nd, Digit, Decimal_Digit_Number | \d | 680 | 64 | [[:digit:]] | 10 |
Nl, Letter_Number | 236 | 12 | |||
No Other_Number | 915 | 72 | |||
P, Punct, Punctuation | 842 | 191 | [[:punct:]] | 32 | |
Pd, Dash_Punctuation | 26 | 19 | |||
Pe, Close_Punctuation | 77 | 76 | |||
Po, Other_Punctuation | 628 | 187 | |||
Print | 1111829 | 24 | [[:print:]] | 95 | |
Ps, Open_Punctuation | 79 | 79 | |||
PythonIdentifierPart | 140101 | 772 | |||
PythonIdentifierStart | 136968 | 661 | |||
S, Symbol, S | 7775 | 233 | |||
Sc, Currency_Symbol | 63 | 21 | |||
Sk, Modifier_Symbol | 125 | 31 | |||
Sm, Math_Symbol | 948 | 64 | |||
So, Other_Symbol | 6639 | 185 | |||
Unicode | \X | 1112064 | 2 | ||
UnicodeIdentifierPart | 140315 | 785 | |||
UnicodeIdentifierStart | 136962 | 663 | |||
Word | \w | 137416 | 712 | [[:word:]] | 63 |
For example, when matching in Unicode mode, matching a \w word character spans a huge number of characters and character blocks. If only an ASCII word character should to be matched, then use [[:word:]] or (?-u:\w) where -u temporarily disables Unicode regex patterns in the parenthesis to match \w in POSIX ASCII as [[:word:]].
Please report bugs as RE/flex GitHub issues.
Please make sure to install the RE/flex library you download and remove old versions of RE/flex or otherwise prevent mixing old with new versions. Mixing old with new versions may cause problems. For example, when new versions of RE/flex header files are imported into your project but an old RE/flex library version is still linked with your code, the library may likely misbehave.
Download RE/flex from SourceForge or visit the RE/flex GitHub repository.
RE/flex software is released under the BSD-3 license. All parts of the software have reasonable copyright terms permitting free redistribution. This includes the ability to reuse all or parts of the RE/flex source tree.
Copyright (c) 2016, Robert van Engelen, Genivia Inc. All rights reserved.
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
(1) Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
(2) Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
(3) The name of the author may not be used to endorse or promote products derived from this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE AUTHOR ``AS IS'' AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
The Free Software Foundation maintains a BSD-3 License Wiki.
Copyright (c) 2016-2025, Robert van Engelen. All rights reserved.